Majority Vote介绍与一致性算法
一、Majority Vote基础介绍
1.1 RLHF和Majority Vote的关系
RLHF的核心思想是让模型学会理解并遵循人类的偏好。这个过程的第一步,就是需要大规模、高质量地"告诉"模型,人类更喜欢什么样的回答。这就是偏好数据集的由来,而"Majority Vote"是产生这个数据集的关键方法。 Majority Vote在RLHF中的核心价值:一种核心的数据处理和决策机制,尤其在构建偏好数据集和训练奖励模型阶段至关重要。 |
1.2 Majority Vote概念
多数投票(Majority Vote)是一种广泛应用于数据标注的标签聚合方法,旨在从多个标注者的输入中确定最终标签,以提高标注数据的一致性和质量。在数据标注中,通常由多个标注者对同一数据点进行标注,多数投票通过选择得票最多的标签作为最终标签。这种方法在众包标注和机器学习训练数据准备中尤为常见,因其简单性和有效性而被广泛采用。
1.3 Vote必要性
如果没有Majority Vote机制,将面临如下的问题:
学习矛盾知识,导致模型认知混乱;价值观偏移增加训练噪声;降低模型学习效率与稳定性
例子 Prompt 1:北京和纽约哪个更适合生活? Person 1选择答案:北京 Prompt 2:北京和纽约哪里过日子更舒服? Person 2选择答案:纽约 尽管两道题实质上表达的是相同的比较问题,若标注员意见分裂且没有投票机制进行多数聚合,大模型学到的是“北京更适合生活”与“纽约更适合过日子”这两种相互矛盾的结论,容易在价值观学习上产生混乱。 |
总结:Majority Vote是RLHF中防止价值观漂移和知识混乱的关键手段,它可以提炼共识,过滤噪声并且实现群体价值观的对齐。
1.4 Vote功能目标
基本目标:在标注平台上实现一个投票机制,多个标注员参与,最终通过多数投票决定数据的标注结果。
-
甲方诉求:
-
算法背后最根本的需求是高质量的标注数据(准确、完整、一致)。
-
明确性: 无歧义的标注输出。
-
一致性: 跨时间、跨标注员的稳定判断。
-
可解释性: 判断逻辑的透明性(如适用)。
-
适当颗粒度: 任务设计时控制 label granularity,与模型输入需求对齐。
-
-
投票机制需要尽可能减少人工错误,同时提高处理速度。
-
-
乙方(标注员)诉求:
-
操作便捷性: 最低认知负荷的投票操作界面。
-
结果透明性: 标注员能否看到投票结果及其原因(如自己的标注被采纳或未被采纳的理由),有助于学习和改进。
-
质量反馈与提升: 如何通过机制实现对标注员的即时质量监督与能力提升?annotator 质量反馈机制/提供错误示例和改进建议
-
任务分配与激励机制: 根据 annotator 的历史一致性与准确性设置信任权重,高质量 annotator 分配关键任务或奖励。
-
-
拆解整体目标
-
公平的投票机制:如何设计机制确保投票过程不受某个标注员偏差影响?
-
效率的优化:如何减少不必要的复杂操作,使标注员能够快速参与投票?
-
反馈机制设计:如何给标注员提供实时反馈,让他们了解投票结果的影响?
-
系统的可扩展性:如何确保这个投票机制能够支持大量标注员并保证投票质量?
-
1.5 Vote基础流程
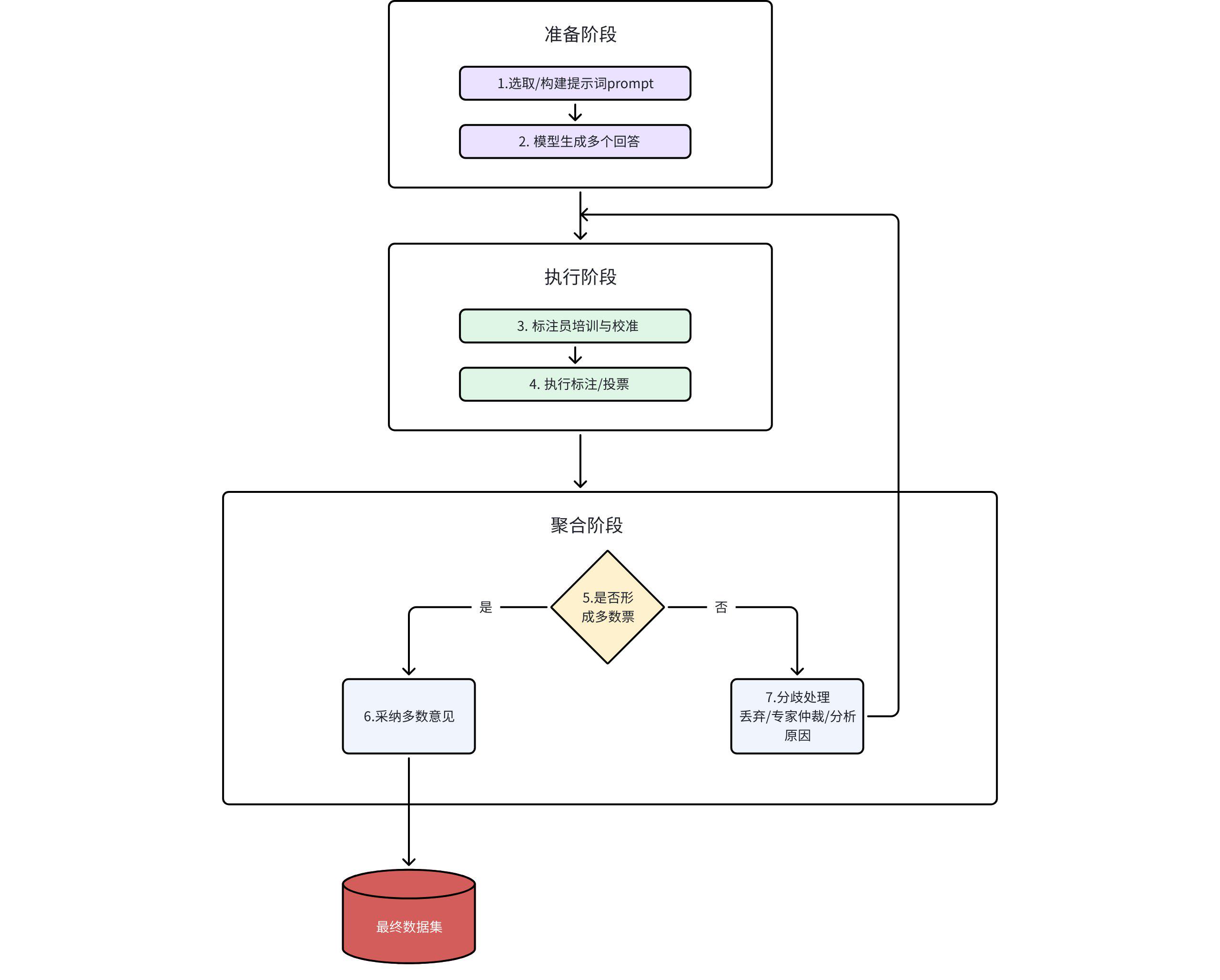
标注数据:
常见来源:训练语料及模型输出、生产环境或真实用户交互日志、公开基准和竞赛数据集、专题/领域专用语料。
采样策略:不确定性采样、错误驱动采样、多样性采样、高价值/高风险场景
1.6 Vote与常见任务种类的适用性
| 任务名称 | 任务描述 | 在RLHF流程中的主要目标 | 数据输出类型 | 多数投票适用性 | 理由与替代方法 |
| 安全分类 | 根据预定义的安全策略(如仇恨言论、暴力)对模型输出进行分类。 | 过滤有害内容,训练安全分类器,评估模型安全性。 | 分类标签(离散) | 高 | 任务具有明确的客观标准和清晰的分类体系。分歧通常被视为错误。替代方法:专家裁决。 |
| 事实性核查 | 验证模型输出中特定声明的真实性。 | 减少模型幻觉,提高回应的可靠性。 | 分类标签(正确/错误/无法核实) | 高 | 存在可供参考的外部“事实真相”。多数投票能有效聚合判断。替代方法:专家裁决。 |
| 指令遵循度判断 | 检查模型输出是否满足提示中的所有明确约束。 | 确保模型能够精确地遵循用户指令。 | 二元或多元分类标签 | 高 | 任务标准客观,易于判断。多数投票是高效的共识机制。 |
| 情绪/语气分析 | 对模型回应的情感色彩或沟通风格进行分类。 | 评估和调整模型的语气,使其更符合用户期望。 | 分类标签(离散) | 中 | 具有一定主观性,但通过详细指南可实现高一致性。分歧可能包含有效信号。替代方法:加权投票。 |
| 比较偏好排序 | 从两个模型生成的回应中选择更优的一个。 | 训练奖励模型,使其学习人类的偏好。 | 偏好关系(A > B) | 低 | 非离散的,输出集不是固定的 每个偏好对为独立样本,不能聚合为“多数”。 多数投票只适用于合并多个标注产生单个结论,不符合“关系输出”为目标的训练需求。 |
| 整体质量评分 | 在一个连续或有序的量表上(如1-7分)为模型回应打分。 | 评估模型整体性能,或作为奖励模型的另一种输入。 | 标量/序数 | 低 | 多数票适用于离散类别决定,而非数值评分。 对连续/序数数据,应使用 均值、中位数,或基于分布的建模(比如区间估计、贝叶斯评分)。 否则会忽略评分的细微差别与排序。 |
| SFT回应撰写 | 人类专家为给定的提示撰写理想的回应。 | 创建高质量的示范数据集,用于监督微调。 | 自由文本 | 不适用 | 目标不是在多个候选中选一个,而是生成高质量单一输出。 若多个专家示例不同,用多数投票选一个示例可能导致质量下降。 SFT 追求最佳示例,不是简单分类选优。 |
二、Vote的应用
2.1 监督微调SFT
通常不直接使用,但会间接地用于数据筛选和构建
SFT 阶段的训练数据是高质量的“指令-回答”对(Prompt-Response Pair)。这个阶段的目标是教会模型如何遵循指令、以何种格式和风格进行回答,而不是学习回答之间的优劣。因此,训练过程本身不涉及比较和投票。
然而,为了获得这些“高质量”的回答,数据标注团队内部可能会使用 Vote 机制。
为什么在这个阶段(间接)做 Vote 标注?
主要目的是质量控制(Quality Control)和数据精选(Data Curation)。
一个指令(Prompt)可能存在多个潜在的、看似都合理的回答。为了确保 SFT 数据的质量是顶尖的(Gold Standard),标注团队可能会:
-
让多个标注员对同一个指令写出回答。
-
或者让一个初始模型对指令生成多个候选回答。
-
然后组织另一批更高阶的标注员或者通过多数投票(MajorityVote)的方式,从这些候选项中选出唯一最佳(The single best)的回答。
这个被“票选”出来的最佳回答,才会进入最终的 SFT 训练集。
SFT 阶段 Vote 数据集的特点和目的
-
特点: 数据集形式通常是 (指令, [候选回答1, 候选回答2,...]),经过投票后,产出的是唯一的 (指令, 最佳回答)。这里的 Vote是一次性的筛选过程,而不是作为模型的直接输入。
-
目的: 确保 SFT模型的学习“榜样”是高质量、无争议、风格统一的。避免模型在初始阶段就学到模棱两可或有缺陷的表达方式。
2.2 奖励模型 (Reward Model, RM) 训练阶段
这是 Vote 标注最核心、最直接的应用阶段
RM 阶段 Vote 数据集的特点和目的
-
特点:
-
最常见的数据集形式是成对比较(Pairwise Comparison)
-
标注员会看到同一个指令下的两个(或多个)回答,并投票选出更好的一个。
-
有时也会采用排序(Ranking)的形式,比如对 4 个回答进行排序 A > B > C> D,这可以分解为多个比较对 (A,B), (A,C), (A,D), (B,C), (B,D), (C,D)。
-
回答的质量可以是多维度的,比如事实准确性、帮助性、无害性、详细程度等。Vote的标准会根据这些维度来综合判断。
-
-
目的:训练一个能够模拟人类偏好判断的奖励模型。这个模型将为后续的强化学习阶段提供密集的奖励信号。
2.3 强化学习策略优化阶段 (PPO, DPO, KTO)
2.3.1. PPO (近端策略优化)
-
有没有使用到 Vote 标注? 不直接使用。
-
原因: PPO 阶段的“裁判”是已经训练好的奖励模型(RM)。
2.3.2. DPO (直接偏好优化)
-
有没有使用到 Vote 标注? 有,直接使用。
-
原因: DPO是一种更“端到端”的方法,它巧妙地跳过了显式训练奖励模型这一步。DPO的论文证明,可以通过一个特殊的损失函数,直接利用偏好数据 (指令, 回答_W,回答_L) 来优化策略模型。这个损失函数的目标是,让策略模型生成回答_W的概率相对于生成回答_L的概率更高。它在数学上等价于用一个隐式的奖励模型进行 PPO 优化。
-
数据集特点和目的: 和 RM 阶段完全一样,使用成对的偏好数据 (指令, 回答_W, 回答_L)。目的是直接将人类的偏好(Vote 结果)注入到策略模型中,使其行为与人类偏好对齐,整个过程更简单、高效。
2.3.3. KTO (Kahneman-Tversky 优化)
-
有没有使用到 Vote 标注? 有,但形式更简化,可以看作一种特殊的 Vote。
-
原因: KTO 的一个创新是它不再需要成对的比较数据。它只需要标注单个回答是“好的”(desirable)还是“坏的”(undesirable)。这可以看作是对单个回答的二元投票(赞成/反对)。这种标注方式成本更低,因为标注员不需要在两个复杂的回答之间做权衡。KTO 的损失函数利用这些“好/坏”标签来鼓励模型多生成“好”的输出,抑制“坏”的输出。
-
数据集特点和目的:
-
特点: 数据集形式是 (指令, 回答, 标签),其中标签是“好”或“坏”。
-
目的: 同样是使模型与人类偏好对齐,但通过一种更低成本的数据标注方式。这对于扩大对齐数据集的规模非常有帮助。
-
三、Agreement 一致性
目标:公平的投票机制
3.1 标注结果之间的一致性
3.1.1 计算方法
-
纯一致率
-
计算方式:统计所有标注之间一致(label完全相同)的比例,例如三人打标,两两间一致次数/总比较次数。
-
适用场景:二分类、多分类、主观性较弱任务。
-
示例:对于N个任务,每个任务有K个标注员,对于每对标注,若标签一致计1,不一致计0,最后求平均。
-
-
复杂任务类型专属度量
-
Labelbox:视觉、文本实体、空间任务采用IoU/重叠/距离/字符重叠/分类一致逻辑。
-
LabelStudio:系统内置多种指标,可依任务类型衡量,也支持 IoU、NER overlap等。
-
-
自定义一致性指标
- Label Studio Enterprise支持用户编写自定义函数并部署,用于匹配特定任务结构。
3.1.2 不同种类的任务计算方法
| 标注类型 | labelbox计算方式 | Label studio |
| Bounding box(框选) / Polygon(多边形) / Mask | IoU 匹配 + 类内平均 | 可通过自定义 metric 使用 IoU;默认可能为 Raw/simple overlap |
| Point(点) / Polyline(折线) | 空间距离一致性 | 可定制函数衡量坐标距离 |
| Text / NER(实体标注) | 字符重叠比例平均 | 默认 Raw Agreement;可写函数按字符重叠或 span overlap |
| Radio(单选分类) | 一致即 100%,否则 0 | Raw Agreement |
| Checklist(多选) | 交集选项数/总选项数比率 | Raw Agreement / 可自定义函数 |
| Free‑form text(自由文本) | 最多采样5条注释 虽然一个 asset(数据行)可以有多个 annotator 的注释,但系统只使用最多 5 条注释参与一致性评估,其他的忽略; 这是为了在大规模打标项目中保证效率与一致性计算的稳定性 |
Raw Agreement 或自定义文本匹配函数 |
| Relationship(关系标注) | 基于子实体一致性组合计算关系一致性 | 可定制函数,或基于多个实体标注级别计算 |
3.2 标注员之间的一致性
3.2.1 标注者间信度(Inter-Annotator Agreement, IAA)
核心思想:超越简单的“一致率”
简单地计算“观察一致率”(Po),即所有标注者意见一致的样本数占总样本数的比例,是不够的。因为即使标注者随机进行标注,他们也可能因为纯粹的运气而达成一致。
因此,这些信度算法都引入了“期望一致率”(Pe)的概念,即在随机情况下期望达成的一致程度。通过从观察一致率中剔除期望一致率的影响,我们可以更真实地反映标注者之间真正的一致性水平。其通用公式框架可以表示为:
信度系数=(Po-Pe)/(1-Pe)
这个公式的含义是:分子代表了实际观察到的、超出偶然机会的一致性,而分母则代表了可能达到的、超出偶然机会的最大一致性。
| 指标 | 介绍 | 置信要求 | 置信区间 |
| Cohen's Kappa | 用途:用于衡量两位标注员之间的一致性。 取值范围:-1到1。1表示完全一致,0表示与随机选择无异,负值则表示一致性甚至不如随机选择。通常认为 Kappa > 0.7 表示较强的一致性。 |
标注员限制:严格限制为两位。这是该算法的固有设计。 样本量限制:没有硬性的最小样本量规定,但业界通常建议: 1. 样本量不宜过小,至少有 30 个样本。 2. 应避免混淆矩阵中出现过多期望频率低于5的单元格,这会影响Kappa值的稳定性。 数据要求:两位标注员必须对完全相同的一批样本进行标注,且分类是互斥的。 |
< 0.00: 一致性差
(Poor) 0.00 – 0.20: 轻微一致 (Slight) 0.21 – 0.40: 一般一致 (Fair) 0.41 – 0.60: 中等一致 (Moderate) 0.61 – 0.80: 高度一致 0.81 – 1.00: 几乎完全一致 通常在实践中,Kappa > 0.7 被认为是标注质量较高、数据可靠的标志。 |
| Fleiss' Kappa | 用途:是Cohen's Kappa的扩展,适用于衡量两位以上的标注员在对项目进行分类时的一致性。这是在有多位标注员时最常用的指标之一。 核心思想:与Cohen's Kappa类似,它同样考虑了偶然性因素,评估的是所有标注员在多大程度上超越了随机一致性。 计算逻辑:它首先计算所有样本的平均一致性,然后与期望的偶然一致性进行比较。 |
标注员限制:要求大于等于两位标注员(通常用于3位及以上)。 样本量限制:建议样本数 ≥ 50,类别分布不能过度倾斜,否则分数偏低 |
同上 |
| Krippendorff's Alpha | 用途:一个非常灵活和强大的IAA指标。 优点: 不受标注员数量限制。 可以处理缺失数据(即某些标注员没有标注部分样本)。 适用于不同类型的数据,包括名义型(如分类)、顺序型(如排序)、区间型和比率型。 在RLHF的排序任务中,Krippendorff's Alpha是一个非常理想的选择。 |
标注员限制:无限制,可以处理任意数量(≥2)的标注员。 数据要求:极其灵活 1. 不要求每个样本有相同的标注员数量,可以自然地处理缺失数据。 2. 对数据类型没有限制,通过不同的“距离函数”可以处理名义、顺序、区间、比率等各类数据。 样本量限制:同样是越多越好。但由于其统计鲁棒性,Alpha在样本量较小或数据不完整的情况下,通常被认为比其他指标更可靠。 |
α < 0.667:
不可靠。应废弃数据,并重新审视标注指南或对标注员进行再培训。 0.667 ≤ α < 0.800: 可以接受。可以基于此数据得出一些试探性的结论 α ≥ 0.800: 非常好。数据可靠,可以充满信心地用于后续分析和模型训练。 对于高质量的RLHF项目,通常将Alpha > 0.8 作为一个重要的质量目标。 |
3.2.1.1 Cohen's Kappa算法介绍:
总体公式:
(Po-Pe)/(1-Pe)
- 观察一致性Po:
计算标注者 A 和 B 对同一样本给出相同标签的次数所占总样本的比例。
Po = 总样本数两人标注相同的样本数/总样本数 - 期望一致率Pe
对于每个标签类别i,计算:
标注者 A 给出该标签的概率 PAi
标注者 B 给出该标签的概率 PBi
然后计算所有标签上,A 和 B 同时随机选择该标签的概率之和: - Pe = ∑PAi⋅PBi
举例:
一个二分类任务,有 10 个样本,标签为 Positive(正)和 Negative(负):
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 标注员A | P | N | P | N | P | P | N | N | P | P |
| 标注员B | P | N | P | N | N | P | N | P | P | P |
- 列出混淆矩阵
| B: Positive | B: Negative | 合计 | |
|---|---|---|---|
| A: Positive | 5 | 1 | 6 |
| A: Negative | 1 | 3 | 4 |
| 合计 | 6 | 4 | 10 |
- 计算Po
A 和 B 同为 Positive:5 个,A 和 B 同为 Negative:3 个,一致总数:5 + 3 = 8**,**总样本数:10
Po=8/10=0.8
- 计算Pe
A 的标签分布:
Positive:6 → PAp=6/10=0.6
Negative:4 → PAn=4/10=0.4
B 的标签分布:
Positive:6 → PBp=6/10=0.6
Negative:4 → PBn=4/10=0.4
Pe=(PAp*PBp) + (PAn*PBn)=0.52
- 计算一致性Kappa值
k=(Po-Pe)/(1-Pe) = (0.8-0.52)/(1-0.52)=0.583
3.2.2 观察一致性例子
Labelstudio-- Raw Agreement
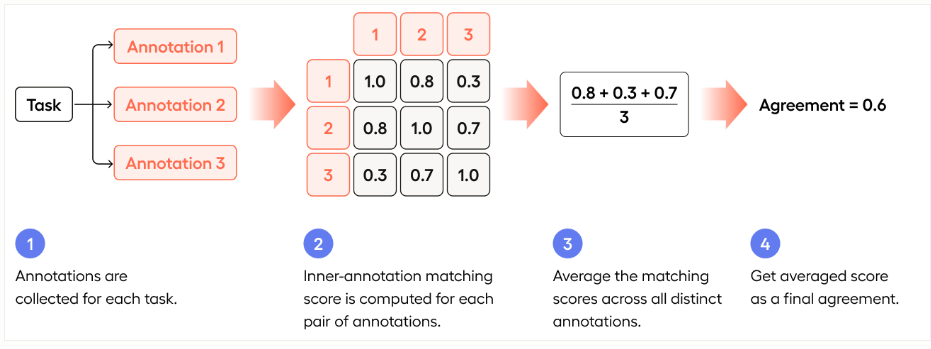
矩阵F(x,y)的含义:标注员x和标注员y的一致度。
结合例子
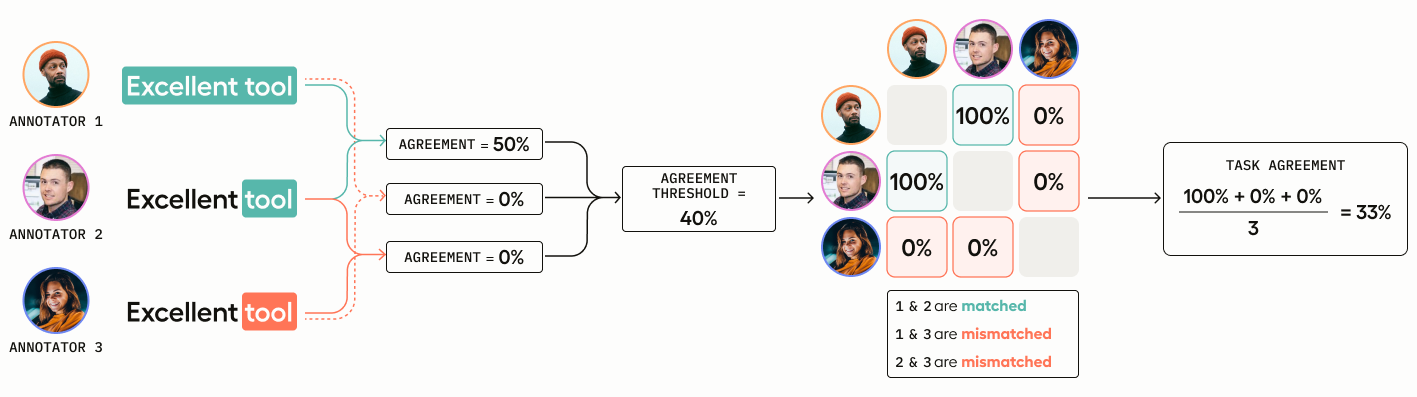
假设有三个注释:
注释 A:把“Excellent tool”标为“positive”
注释 B:把“tool”标为“positive”
注释 C:把“tool”标为“negative”
生成的一致性分数为:
A vs B = 50%(文本跨度交集一致);
A vs C = 0%;
B vs C = 0%。
设阈值为 40%,则 A 和 B 被认为一致(100%)。最终任务一致性评分 = (100 + 0 + 0) / 3 = 33.33%
3.2.3 标注员数量与一致性置信度关联
一致性分数置信度因素
| 因素 | 影响说明 |
|---|---|
| 标注员数量 | 少量标注员(2–3人)时,一致性分数容易受个体偏差影响,可能不稳定;标注员人数越多,统计估计越稳健(尤其是 Fleiss' Kappa、Krippendorff's Alpha 会更可信)。 |
| 样本数量 | 样本数量越少,一致性分数波动越大。通常建议样本数量 >30 才能粗略评估,>100 才更可信。 |
| 类别分布是否平衡 | 如果标注类别极度不平衡(例如90%都选“A”),即使一致,分数也会偏低或偏高。 |
建议(以实际项目情况为准)
| 场景 | 建议人数 | 原因 |
|---|---|---|
| 简单分类任务 | ≥3 人 | 投票+Fleiss Kappa 足够 |
| 复杂排序/多维度任务 | ≥5 人 + Alpha | 更好捕捉模糊与冲突,一致性可信 |
| 大规模任务 | 重叠标注20%(比如所有任务中20%由多人重复标注,其余交给单人标注,节省成本同时保留一致性评估依据。) | 成本可控,一致性监控 |
| 有成本限制时 | 3人主标+专家复查 | 保底质量 |
3.3 多维度聚合任务一致性方案
通常对多维度聚合任务,会分别对每个维度计算上述指标以评估标注者在该维度上的一致性;如果任务设计中同时有一个整体评价(例如总体满意度),则对该整体分数也做一次一致性分析。例如,在诗歌评价时可分别统计“格律”、“意境”等维度的一致性分数,也可统计评分者给出的综合分的一致性。另外,复杂标注任务往往需要训练标注者和细化指引,以提升一致性。
3.3.1 聚合策略
3.3.1.1 最终偏好直接采纳
流程: 直接看标注员对主任务的最终投票。
举例:标注员对2首诗(A和B)在4个维度上进行1-5分的打分,并做出最终偏好选择。
-
比如最终偏好的一致性结果是“诗A更好”,那么就生成一条训练数据:(prompt, answer_A, answer_B)。
-
子任务的评分不直接参与生成这条win/loss数据。
子任务评分的用途:
-
数据过滤和加权: 只有当投票获胜的答案(如诗A)在其关键子任务维度上的平均分也显著高于失败的答案(诗B)时,才认为这是一条高质量的偏好数据。反之,如果诗A赢了,但所有子任务得分都低于诗B,这条数据就可能被视为“噪声”或“异常”,可以在训练时被丢弃或降低其权重。
-
Reward模型的设计: 在更高级的RLHF中,Reward模型 (RM) 不仅可以预测一个单一的偏好分数,还可以被设计为预测一个多维度的分数向量。在这种模式下,子任务的评分可以直接作为训练RM的目标。这样训练出的RM不仅知道“谁更好”,还知道“好在哪里”,这能为后续的模型分析提供更丰富的洞察。
3.3.1.2 加权分数决策(rubric设定)
流程: 忽略标注员的最终偏好选择,完全基于子任务的一致性评分来决定胜负。
举例:
-
定义权重: 为每个子任务分配一个权重(例如:意境40%,音律30%,语言20%,排版10%)。
-
计算加权总分: 对每个标注员的打分,计算出两首诗的加权总分。
-
Score_A = 0.4*意境_A + 0.3*音律_A + 0.2*语言_A + 0.1*排版_A
-
Score_B = 0.4*意境_B + 0.3*音律_B + 0.2*语言_B + 0.1*排版_B
-
-
多数投票: 看多数标注员的计算结果中,是A的总分高还是B的总分高,以此决定win/loss。
3.3.2 标量奖励与多维奖励
| 标量奖励模型 | 多维目标奖励模型 | |
| 简介 | 用一个标量(单一分数)评估回答的优劣 | 用多个维度(如诚实性、相关性等)分别打分,再聚合成最终奖励 |
| 理论基础 | 基于Bradley-Terry模型等成对比较排序;训练目标是最大化胜者得分减失败者得分差值 | 基于多目标学习(Multi-objective learning)与可解释性建模;通常融合多个子目标 |
| 训练数据 | (prompt, answer_win, answer_loss) | (prompt, answer, [dim_1_score, dim_2_score, ...]) 每维打分组成的标签 |
| rm输出形式 | 单一分数(reward),表示回答的综合好坏程度 | 多个维度得分(如 helpful: 4.3, honest: 3.8),可聚合为总 reward,也可解释 |
| 优势 | 简洁直观; 训练收敛快,易于优化 RL 模型; 与 PPO 等算法天然兼容 |
可解释性与可诊断性好; 可控生成; 更精细的奖励信号,适合细粒度调优与安全控制 |
| 劣势 | 不可解释,胜负原因不明; 模型学到的“偏好”可能掺杂噪音 |
训练复杂,需大量带标签数据; 聚合机制(如维度权重)不易确定 |
四、批判性分析与高级替代方案
4.1 多数投票在精细化对齐中的局限性
-
多数派的暴政:多数投票机制会系统性地压制少数派的观点。在处理伦理判断、文化细微差异等主观性强的任务时,少数派的意见往往不是“噪声”,而是反映了社会多样性的有效视角。通过多数投票将这些观点“聚合掉”,可能会导致模型产生偏向于主流人口或文化的偏见,从而损害其公平性和包容性。
-
信息丢失:多数投票将一个丰富的投票分布简化为单个标签,从而丢弃了关于共识程度或模糊性的宝贵信息。例如,一个5票对4票的决策和一个9票对0票的决策,在多数投票机制下会得到完全相同的结果。然而,前者表明了任务的高度模糊性或争议性,这本身就是模型需要学习的重要信号。
-
不适用于复杂反馈:多数投票无法处理非分类数据,如偏好排序、标量评分或自由文本解释。然而,这些更丰富的反馈形式对于实现细粒度的模型对齐至关重要。
-
易受标注员偏见影响:多数投票假设所有标注员的技能水平和公正性是均等的。实际上,一群技能较低或带有系统性偏见的标注员可以轻易地在票数上压倒少数专家,从而产生一个低质量的共识标签。
4.2 高级聚合框架
加权投票(Weighted Voting):
-
描述:该方法根据标注员的可靠性、专业知识或历史表现为他们分配不同的权重。这可以有效防止低质量的标注员主导共识结果。
-
实现:一种常见的实现方式是,通过计算标注员与“黄金标准”数据集(由专家预先标注)或与其他标注员共识的一致性来评估其“声誉分数”。在标注平台上,可以为更高等级的标注员赋予更高的投票权重。
专家裁决(Expert Adjudication):
-
描述:对于分歧较大、模糊性高或风险高的标注项,系统不再依赖纯粹的算法聚合,而是将这些案例上报给一位或多位资深标注员或领域专家进行最终裁决。
-
权衡:这种方法能显著提高数据质量和一致性,但其可扩展性差,成本也远高于自动化方法。
分布偏好学习(Distributional Preference Learning, DPL):
-
描述:这是一种范式上的转变。它不再试图将人类反馈聚合成一个单一的“基本事实”,而是将完整的偏好分布本身作为学习信号。其目标是训练一个能够预测偏好分数概率分布的模型,从而直接捕捉和建模模糊性与分歧。
-
意义:这种方法承认,对于许多主观问题,并不存在唯一的“正确”答案。一个真正对齐的模型应该能够在其回应中反映这种不确定性,而不是强行给出一个看似确定的答案。
-
未来:DPL和多维目标奖励模型结合,多维目标RM 关注的是**“好”的构成,分布偏好学习 (DPL) 关注的是对“好”的共识程度,**两者是正交的、可以互补,可以完美地结合起来,形成一个极为强大和精细的反馈系统。
-
训练数据:
- 成对偏好分布
{
"prompt": "写一首关于夏日雷雨的诗",
"answer_A": "...",
"answer_B": "...",
"annotations": {
"votes_for_A": 6,
"votes_for_B": 3,
"votes_for_tie": 1,
"total_annotators": 10
}
}
在这个例子中,有10位标注员参与。6人认为A更好,3人认为B更好,1人认为两者相当。 |
- 多项偏好排序分布
场景:Prompt: "请解释什么是黑洞",候选答案: [response_A, response_B, response_C, response_D],标注员数量: 100人
{
"prompt_id": "prompt_12345",
"prompt_text": "请解释什么是黑洞",
"candidate_responses": [
{
"response_id": "A",
"text": "黑洞是时空曲率大到光都无法逃逸的天体..."
},
{
"response_id": "B",
"text": "一个黑洞是宇宙中的一个区域,引力非常强..."
},
{
"response_id": "C",
"text": "想象一张蹦床,放一个保龄球在中间..."
},
{
"response_id": "D",
"text": "黑洞是由大质量恒星在生命末期坍缩形成的..."
}
],
"annotations": [
{
"annotator_id": "user_001",
"ranking": ["B", "A", "D", "C"] // 表示该用户认为 B > A > D > C
},
{
"annotator_id": "user_002",
"ranking": ["B", "D", "A", "C"] // 表示该用户认为 B > D > A > C
},
{
"annotator_id": "user_003",
"ranking": ["A", "B", "D", "C"]
}
// ... 还有97条类似的记录
]
}
|
选择何种标签聚合方法,实际上隐含了项目对“价值”和“对齐”的根本性理论假设。选择多数投票,意味着相信存在一个单一的、客观的“真理”,并且这个真理可以通过多数人的共识来发现。这是一种“真理中心”的对齐观。相比之下,选择分布偏好学习等更复杂的方法,则意味着承认价值是主观的、多元的,一个对齐的AI系统应该能够建模并反映这种多样性。这是一种“价值多元主义”的对齐观。
参考:
https://docs.humansignal.com/guide/stats
https://docs.humansignal.com/guide/custom_metric
https://docs.labelbox.com/docs/consensus
https://docs.labelbox.com/docs/quality-analysis
https://aclanthology.org/2024.findings-emnlp.620/