一、整体介绍
概述
Terminal-Bench 面向 hard, realistic tasks in command line interfaces,每条任务都包含自然语言题面、独立 Docker 环境、测试脚本、参考解法(oracle solution),并通过执行 harness 将模型真正放进 terminal 环境完成端到端任务。即便是 frontier 级模型,在公开 Terminal-Bench 2.0 上仍未达到饱和,说明这类任务依然是极高信噪比的 agent 能力测量工具。
围绕这一范式构建的 TB2.0 数据资产,天然具备以下特征:
-
Harness-backed:任务是运行在可控环境中的真实执行过程 -
Verifier-driven:结果由测试、Oracle、结构化校验和环境反馈判定,不依赖人工主观打分 -
Long-horizon:大量任务不能一步完成,需要多轮观察、规划、尝试与修正 -
Multi-step:需要跨文件、跨工具、跨状态推进,而不是单点生成答案 -
RL-env friendly:环境、反馈、结果判定三者完整,适合对接 outcome-based RL 与 RL rollout -
Large-context:典型任务包含日志、代码仓库、配置、测试输出、二进制/文本工件等大上下文信息
数据价值
数据资产形态
| 层级 | 组成 | 作用 |
|---|---|---|
| 任务层 | instruction、目标、输入输出约束、任务工件 | 定义模型需要完成的真实 terminal 任务 |
| 环境层 | Docker 环境、依赖约束、标准运行入口 | 保证任务在受控 harness 中稳定执行 |
| 验证层 | 测试脚本、oracle、结构化校验 | 提供可信 verifier 与 reward signal |
| 轨迹层 | 运行日志、执行轮数、失败分布 | 支持错误分析、trajectory mining、RL rollout |
| 元数据层 | domain、tags、任务方向、pass rate、返修次数、项目期数等 | 支持分层采购、定向切包、效果诊断 |
| 治理层 | 相似性检查、预检、复审、返修、入库状态 | 保证任务质量、可复用性与可解释性 |
能力提升映射
| 能力维度 | TB2.0 提供的训练信号 | 典型提升结果 |
|---|---|---|
| Terminal-native execution | 文件读写、命令执行、环境观察、脚本运行、日志读取 | 模型从"会解释"转向"会执行" |
| Long-horizon planning |
多轮状态更新、跨回合目标保持、阶段性纠偏 | 提升复杂任务的持续完成率 |
| Multi-step repair loop | 改代码 -> 跑测试 -> 读错误 -> 修复 -> 回归验证 | 提升 coding agent 的闭环收敛能力 |
| Verifier awareness | 结果以测试和环境状态为准,而不是语言表面合理性 | 提升"做对事"而非"说对话"的能力 |
| Large-context reasoning | 处理超长日志、代码库、配置、文档、输出工件 | 提升 token window size 压力下的信息保持能力 |
| Hard engineering generalization | 安全、编译器、并发、系统、性能优化、格式解析 | 补齐长尾高价值工程能力 |
工具级能力提升
| 工具 / 技术栈 | 可提升的具体能力 | 典型训练动作 |
|---|---|---|
| MySQL / PostgreSQL / SQLite / Redis | 数据库查询、表结构理解、索引分析、迁移脚本编写、状态恢复、结果校验 | 读 schema、写 SQL、做表同步、修复查询逻辑、验证结果一致性 |
| grep / sed / awk / find | 文本搜索、批量替换、日志过滤、配置扫描、命令行排障 | 在仓库或日志中定位关键行、批量修补配置、提取结构化字段 |
| jq / csvkit / JSON / CSV / Parquet / YAML / XML | 结构化数据处理、ETL、格式转换、字段对齐、报告生成 | 做 JSON/CSV 转换、处理 Parquet 工件、对齐 YAML 配置、抽取 XML 字段 |
| curl / wget / HTTP / TLS | 网络请求复现、接口调试、证书校验、下载与完整性验证 | 重放请求、验证端口与证书、定位协议或网络层错误 |
| pytest / unittest | 测试复现、失败定位、回归验证、断言驱动修复 | 运行测试、阅读 assertion 失败、修复实现、重新回归 |
| make / CMake / Bazel / configure | 构建系统理解、依赖处理、编译调试、产物打包 | 修 build 脚本、处理依赖冲突、完成从源码到产物的闭环 |
| ps / top / lsof / ulimit | 进程排障、端口冲突定位、资源瓶颈分析、运行时诊断 | 看进程状态、找 FD/端口占用、判断资源限制导致的失败 |
| tar / gzip / rsync / chmod / ACL | 归档、分发、权限修复、部署准备 | 打包工件、同步目录、修权限、保证交付物可运行 |
| Python / Bash / Shell | 自动化脚本编写、命令编排、数据胶水层实现 | 写 CLI 工具、写 glue code、把多个步骤串成可执行 pipeline |
二、数据详情(1000 条)
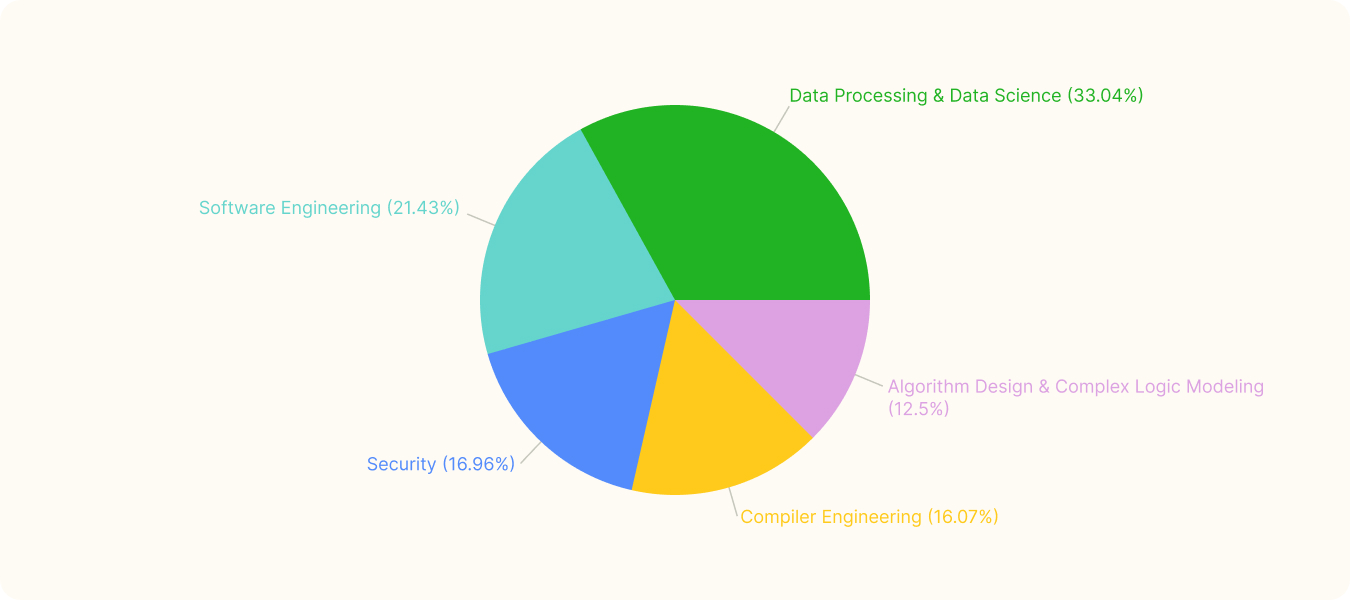
Domain 分类占比
LeaderBoard
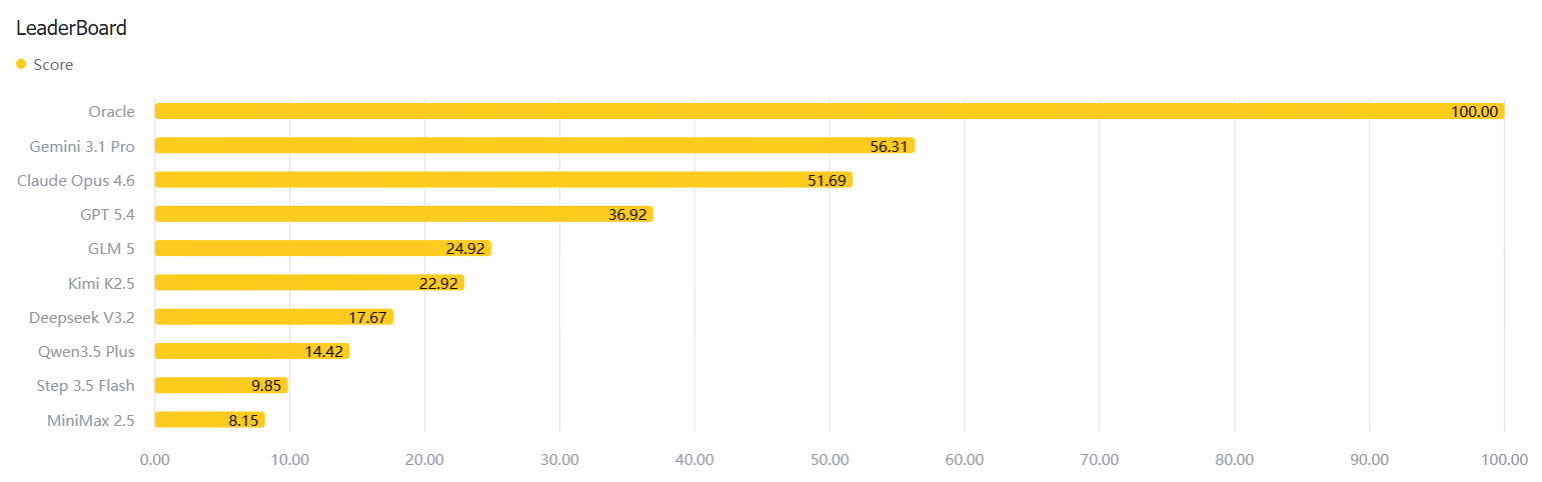
注:Oracle 是基于标准答案的理论满分(100%),作为对比标尺。即任务是明确可解的,模型分数低是因为终端执行、状态跟踪、自纠和 verifier 适配能力仍然不足。
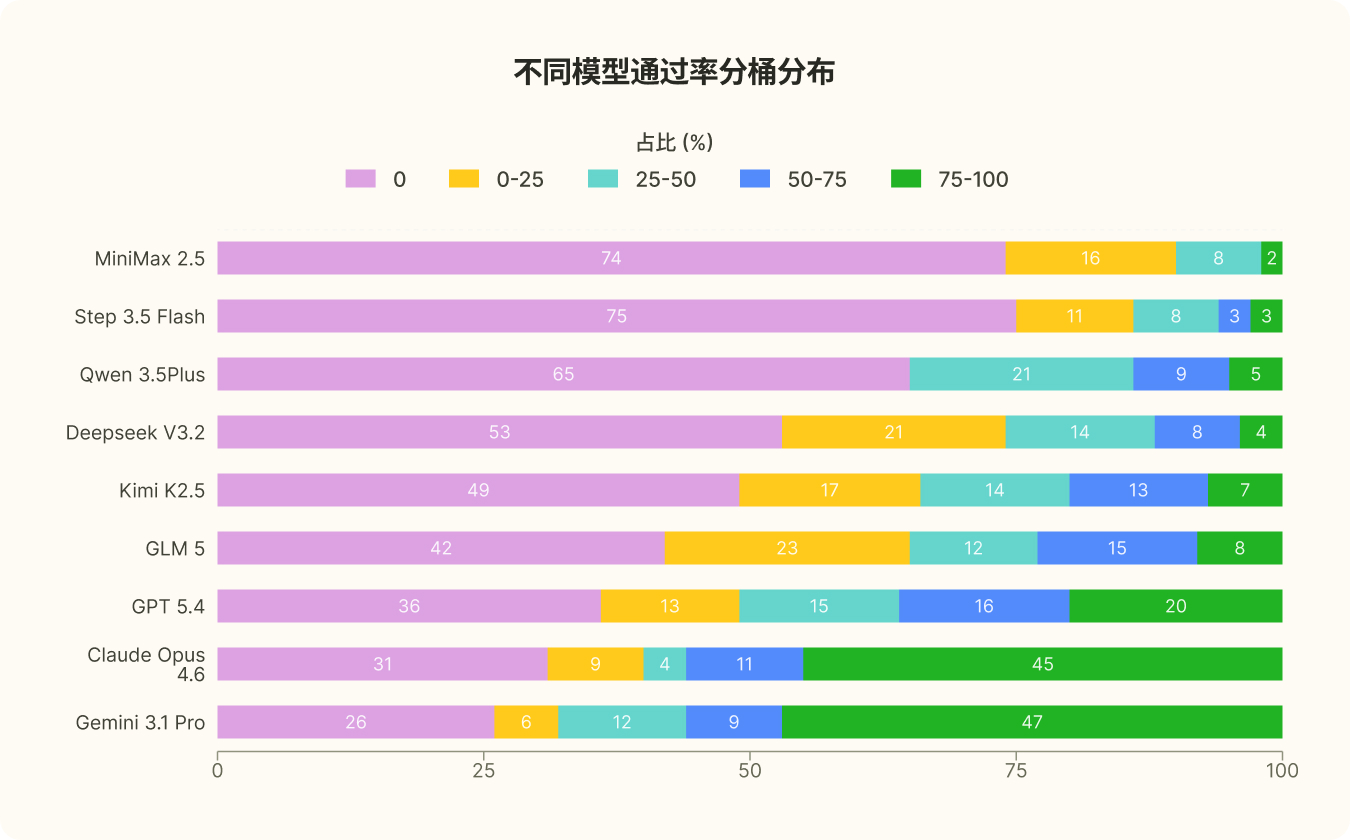
PassRate
核心领域基准评测(Top 5 Domains)
| Domain | 图表 |
|---|---|
| Data Processing & Data Science |
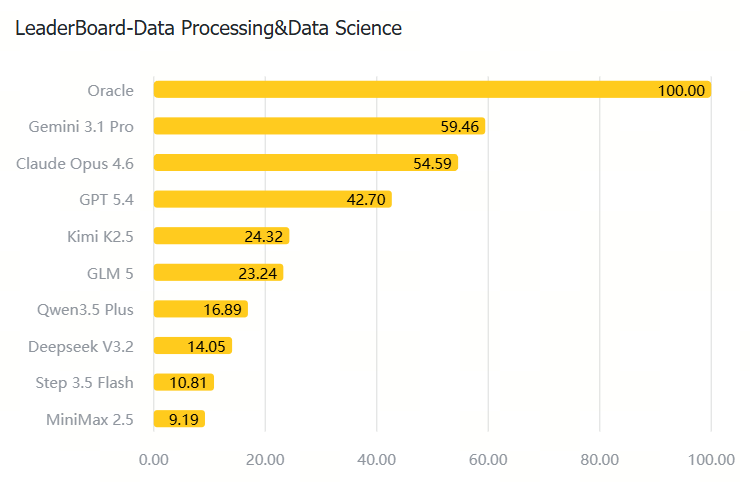 |
| Software Engineering |
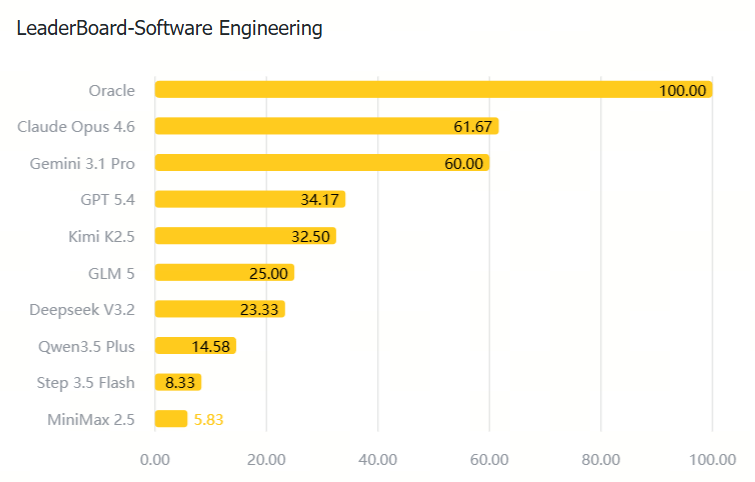 |
| Security | 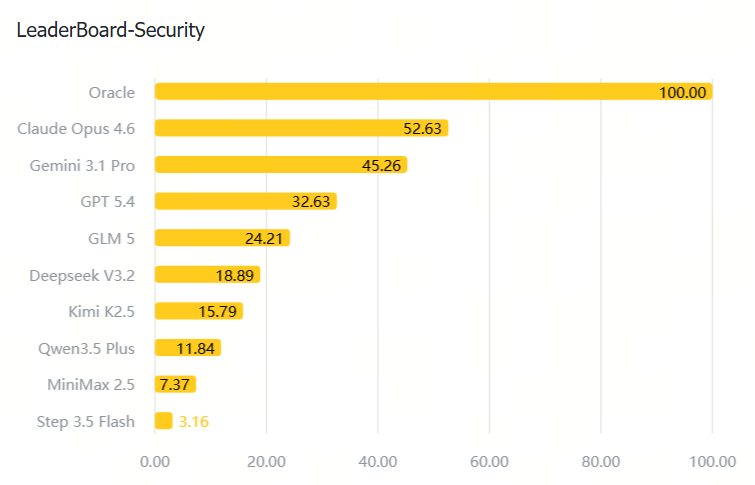 |
| Algorithm Design & Complex Logic Modeling | 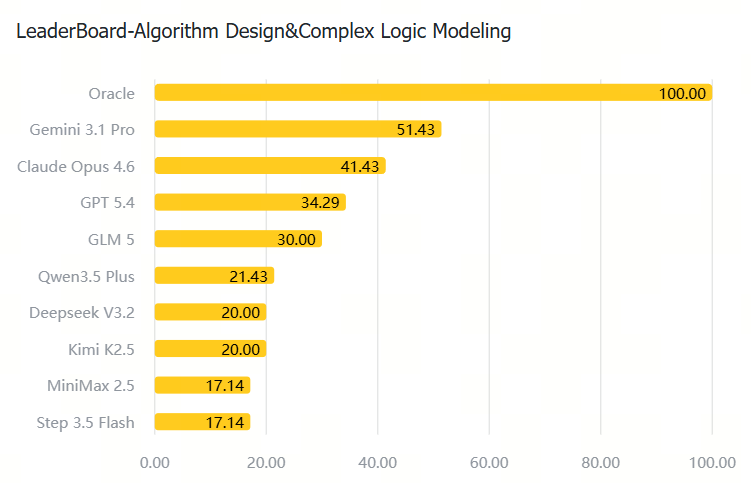 |
| Compiler Engineering | 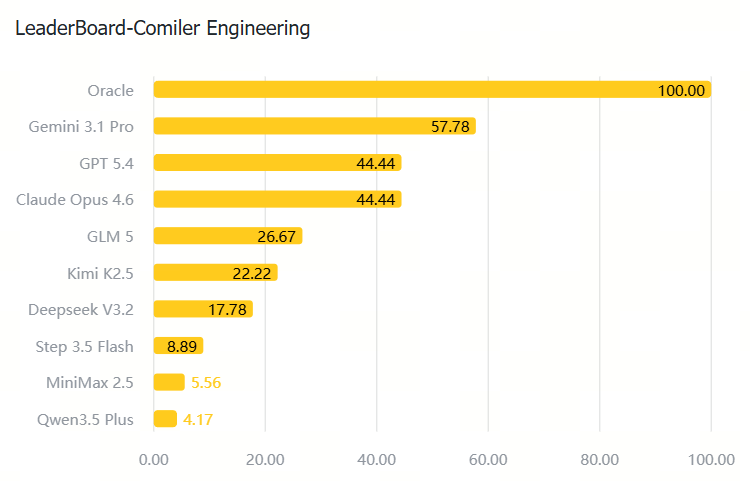 |
交互轮数(Turns)
Turns 是理解 long-horizon 与 multi-step 价值的关键指标。TB2.0 中的大量任务需要多轮执行、重试、定位、回归验证。
从轨迹分布看:
-
44.1%的成功轨迹需要20轮以上交互 -
59.7%的失败轨迹需要20轮以上交互 -
10.8%的成功轨迹需要40轮以上交互 -
19.3%的失败轨迹需要40轮以上交互
三、数据生产与治理
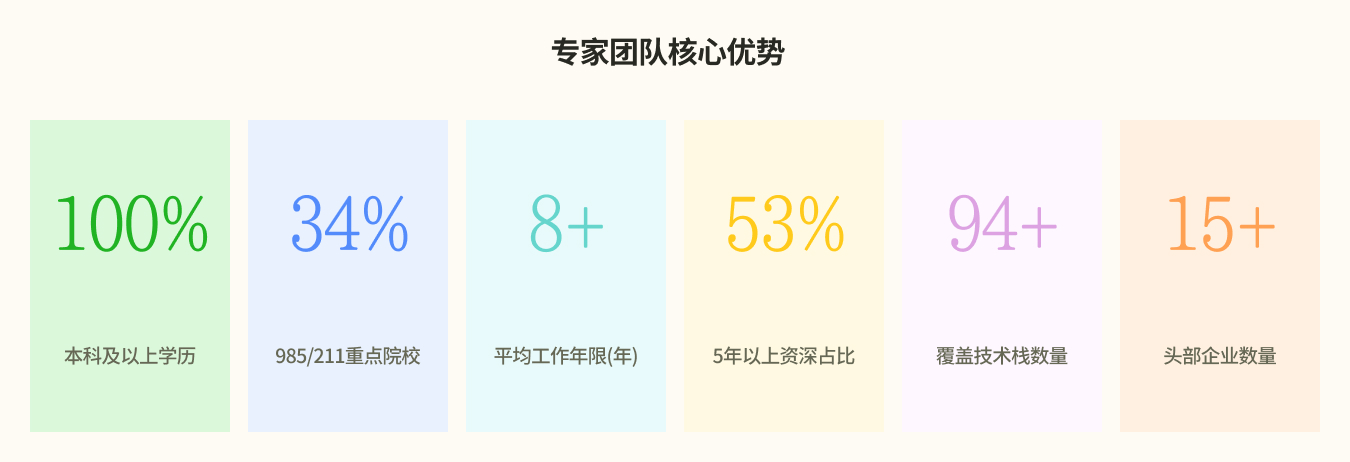
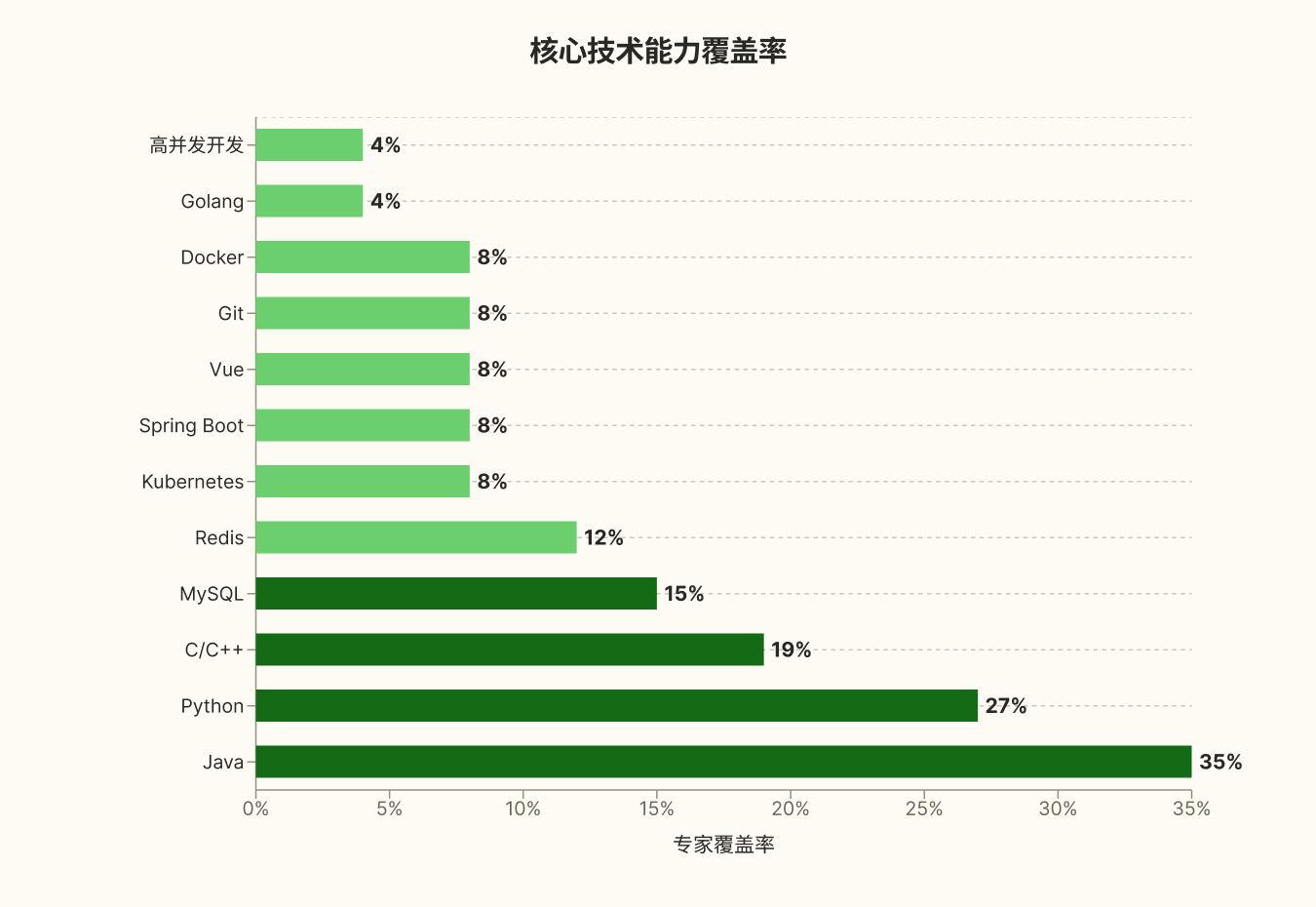
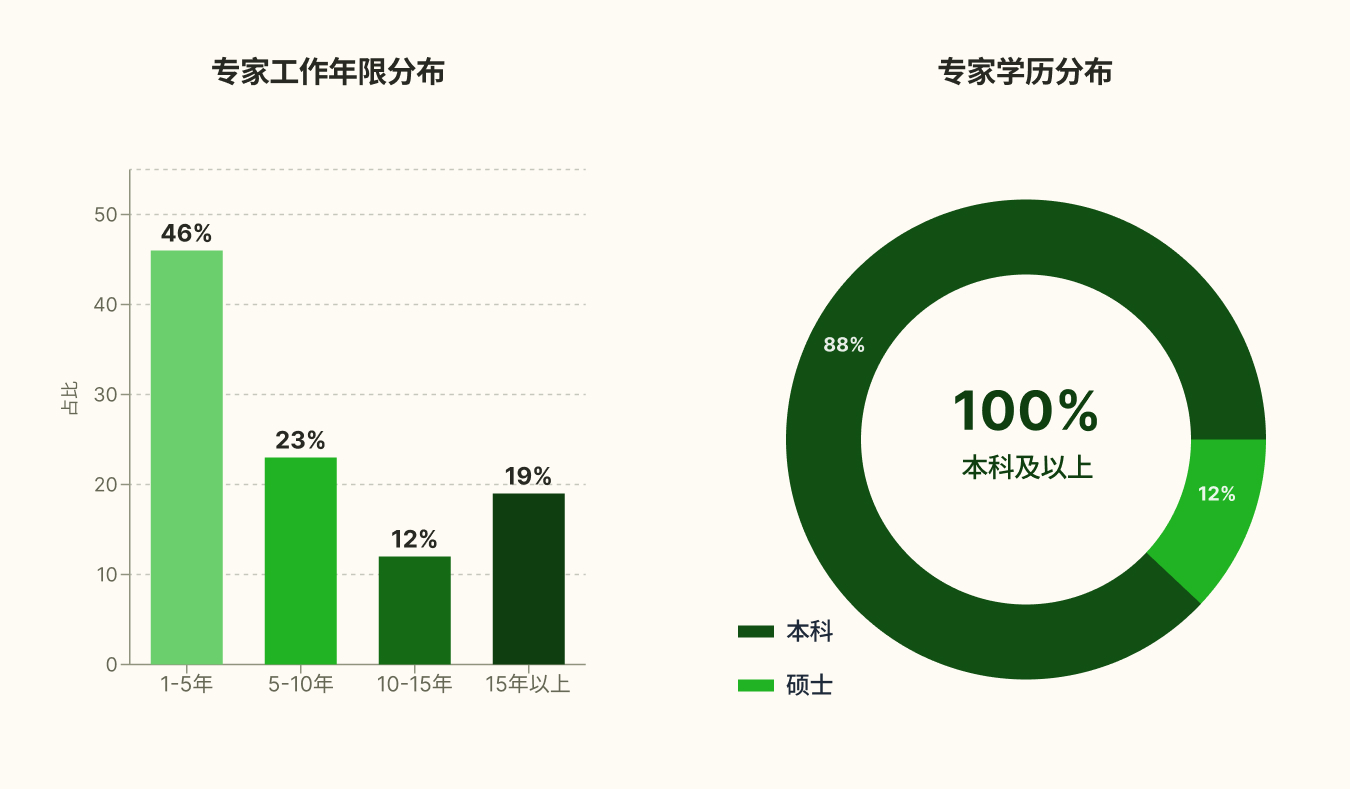
专家画像


生产流程
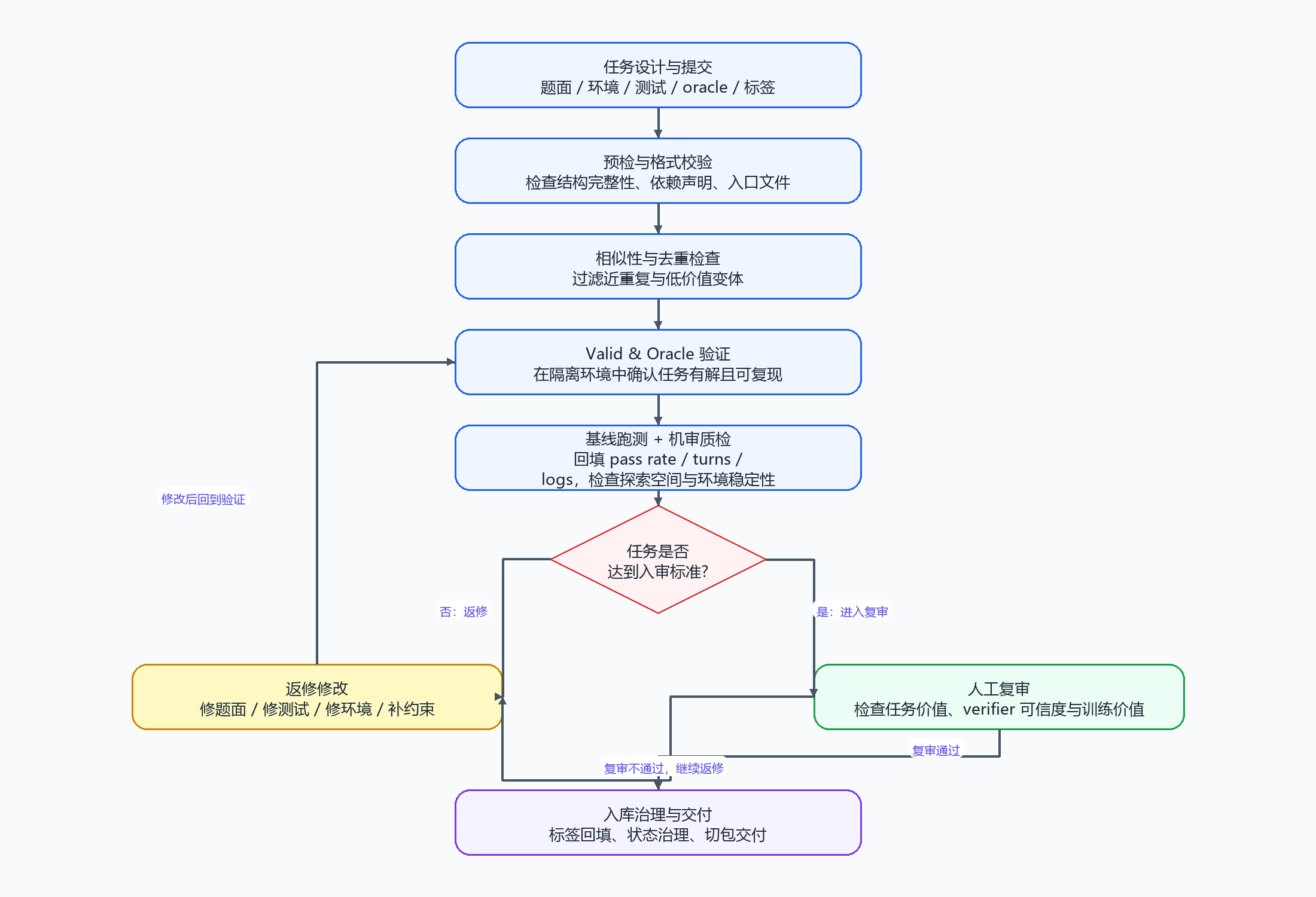
为保证 TB2.0 评测与训练数据的专业性、稳定性、可复现性与能力区分度,所有任务均由专家按统一规范设计,并经过自动化验证与多轮人工复审,形成标准化生产流程:
-
专家基于真实 terminal、coding、tool-use 与工程调试场景设计任务,严格控制任务难度、探索空间与多步复杂度,确保任务人工可稳定完成、模型具备明确提升空间;
-
采用统一任务结构与标准化任务包配置,完整包含题面、运行环境、测试脚本、参考解法(oracle)及必要元数据,保障任务可追溯、可复检、可批量调度;
-
指令仅描述目标、约束与交付标准,不直接暴露解题路径或中间策略,明确工具边界与环境限制,避免将任务退化为说明书式操作题;
-
基于隔离、可控、可复现的运行环境构建任务场景,尽可能消除外部网络依赖、随机波动与脆弱环境因素,保证 verifier 信号稳定可靠;
-
通过 Valid & Oracle 验证确认任务有解、可跑、可复现,并结合基线模型跑测回填 pass rate、执行轮数、失败分布等信号,对任务难度、long-horizon 特征与 multi-step 价值进行初筛;
-
结合相似性检查、机审质检与人工审核,对题面质量、测试覆盖、环境稳定性、奖励信号可信度及防作弊设计进行多维审查,过滤低价值、近重复或不可收敛任务。
数据控制
一面千识Terminal-Bench 2.0数据集致力于为 Outcome-based RL提供高质量的训练数据。我们的审核体系基于第一性原理设计,确保产出的每一条数据满足三大核心指标:任务高价值(具备探索空间)、奖励信号可信(测试公平精准)、运行结果稳定(100%可复现)。
一、 "五级漏斗"数据验证流程
我们构建了一套工业级的"机器自动化流水线 + 专家深度复核"的多级漏斗把控体系,确保数据纯净度:
-
数据独特性检测 (Similarity Check):通过哈希去重、向量粗筛与语义精筛三层防线,防止训练集出现重复数据,保障数据多样性。
-
解法与环境验证 (Valid & Oracle):在隔离的 Docker 环境中自动运行参考解法(Solution),必须 100% 跑通所有测试用例,从源头确保题目在给定环境下绝对"可解"。
-
多维度静态质量审查 (Quality Assurance):审核专家介入审查 Prompt 清晰度、Prompt跟测试匹配度、工程实现规范及防作弊机制,确保没有泄露答案或包含不合理的外部依赖。
-
基于轨迹的动态深度诊断 (Log Analysis & Root Cause):根据SOTA模型运行的日志,逆向推导 Agent 表现与失败根因,排查极为隐蔽的测试逻辑漏洞。
-
难度兜底:运行Passrate@8(GLM4.7)量化题目难度,直接拦截通过率过高(≥0.625)的缺乏挑战性任务。
二、 严苛的三大核心数据标准
一面千识Terminal-Bench 2.0 对入库任务执行严苛的验收标准:
-
标准一:极高的探索空间
-
拒绝说明书式任务:严禁采用"按部就班"的指令或透题式提示词。优秀的任务必须像"解谜游戏"。
-
六维能力考量:通过路径复杂度、决策点数量、反馈循环等六大维度评估任务价值。模型必须通过真实的观察、推理与多轮试错才能获得成功,从而提供极高的 RL 训练价值。
-
-
标准二:恰到好处的测试设计
-
防误杀(防过严):严格校验测试用例,杜绝测试代码硬编码未要求的细节(如未规定的文件名、固定字符串格式等),确保兼容模型的等价正确解法。
-
防投机(防过松):防止测试用例只做表面检查(如仅验证文件存在而不查内容),要求覆盖题面约束的所有功能点与核心边界条件,保障 Reward(奖励信号)极度可信。
-
-
标准三:工业级的工程稳定性
-
环境零波动:强制禁止任务依赖外部网络(网络波动)、系统时间戳(Flaky 测试)以及未固定的随机数。
-
依赖强锁定:所有底层环境依赖项与工具链均使用官方稳定镜像源并实施严格的版本锁定,确保同一套解法无论运行多少次,都能获得完全一致的评分。
-
四、Sample Data
Sample 1:termzip-ansi
| 字段 | 内容 |
|---|---|
| 任务名称 | termzip-ansi |
| 任务领域 | Data Processing |
| Tags | python,optimization,performance-optimization,terminal,video-processing |
| 模型通过率 (PassRate@5 Terminus2 + model) |
Claude 4.6 Opus: 20% GPT 5.4: 0% Gemini 3.1 Pro: 40% GLM 5: 0% DeepSeek-V3.2: 0% Qwen3.5-Plus: 0% |
| Claude 4.6 Opus 运行消耗评估 (Pass@5) |
平均交互轮次:59.8 平均输入 Token (Avg. Input Tokens):3304980 平均输出 Token (Avg. Output Tokens):47387 平均总消耗 Token (Avg. Total Tokens):3352366 |
| 训练的模型能力 | 二进制格式解析、ANSI / terminal 协议理解、增量式状态更新、严格 stdout 约束执行、压缩与性能权衡 |
| 下载链接 | https://tb-sample.tos-cn-beijing.volces.com/2026v101/termzip-ansi.zip |
Sample 2:benchmark-redis-nogil
| 字段 | 内容 |
|---|---|
| 任务名称 | benchmark-redis-nogil |
| 任务领域 | Concurrency Engineering |
| Tags | C,performance-optimization,concurrency,python-extension,redis |
| 模型通过率 (PassRate@5 Terminus2 + model) |
Claude 4.6 Opus: 60% GPT 5.4: 20% Gemini 3.1 Pro: 40% GLM 5: 0% DeepSeek-V3.2: 0% Qwen3.5-Plus: 0% |
| Claude 4.6 Opus 运行消耗评估 (Pass@5) | 平均交互轮次:54.6 平均输入 Token (Avg. Input Tokens):1425047 平均输出 Token (Avg. Output Tokens):20457 平均总消耗 Token (Avg. Total Tokens):1445504 |
| 训练的模型能力 | make / configure / 编译工具链、Redis 本地 benchmark、Python runtime 语义、C extension 构建、并发调试、性能实验报告生成 |
| 下载链接 | https://tb-sample.tos-cn-beijing.volces.com/2026v101/benchmark-redis-nogil.zip |
Sample 3:urllib3-crlf-injection
| 字段 | 内容 |
|---|---|
| 任务名称 | urllib3-crlf-injection |
| 任务领域 | Security |
| Tags | security,python,debugging,code-vulnerability,common-weakness-enumeration |
| 模型通过率 (PassRate@5 Terminus2 + model) |
Claude 4.6 Opus: 0% GPT 5.4: 60% Gemini 3.1 Pro: 0% GLM 5: 0% DeepSeek-V3.2: 20% Qwen3.5-Plus: 0% |
| Claude 4.6 Opus 运行消耗评估 (Pass@5) |
平均交互轮次:52.8 平均输入 Token (Avg. Input Tokens):1605585 平均输出 Token (Avg. Output Tokens):13801 平均总消耗 Token (Avg. Total Tokens):1619386 |
| 训练的模型能力 | urllib3 请求链路理解、输入校验、漏洞修复、CWE / CVE 映射、pytest 回归验证、结构化安全报告生成 |
| 下载链接 | https://tb-sample.tos-cn-beijing.volces.com/2026v101/urllib3-crlf-injection.zip |
Sample 4:webpack-to-vite-migration
| 字段 | 内容 |
|---|---|
| 任务名称 | webpack-to-vite-migration |
| 任务领域 | Software Engineering |
| Tags | build-tools,python,react,vue,web,js |
| 模型通过率 (PassRate@5 Terminus2 + model) |
Claude 4.6 Opus: 0% GPT 5.4: 40% Gemini 3.1 Pro: 0% DeepSeek-V3.2: 0% Qwen3-Coder-480B: 0% |
| Claude 4.6 Opus 运行消耗评估 (Pass@5) | 平均交互轮次:32.0 平均输入 Token (Avg. Input Tokens):873935 平均输出 Token (Avg. Output Tokens):21631 平均总消耗 Token (Avg. Total Tokens):895566 |
| 训练的模型能力 | package.json 更新、前端构建工具迁移、React / Vue 识别、配置语义转换、多页面 HTML 注入、批量脚本自动化、低风险仓库改造 |
| 下载链接 | https://tb-sample.tos-cn-beijing.volces.com/2026v101/webpack-to-vite-migration.zip |