基准框架:MCPMark(https://github.com/eval-sys/mcpmark)
一、整体介绍
本数据集基于 MCPMark 框架构建。MCPMark 是目前业界最系统的 MCP(Model Context Protocol)压力测试基准,由 NLP 领域顶级团队主导设计,旨在评估大模型在真实 MCP 工具链中的 Agent 能力。MCPMark 的权威性体现在以下几点:
-
主流厂商参与对标:Claude Opus、GPT 系列、Gemini 系列均在其榜单中参与评测,是衡量模型 Agent 能力的行业参照坐标。
-
真实工程场景:任务覆盖 Filesystem、PostgreSQL、GitHub、Playwright 四类真实工作场景,而非人造竞赛题。
-
严格的程序化验证:每个任务配套
verify.py,pass/fail 由确定性规则判定,排除主观因素。 -
多步骤工具调用链:每条 trajectory 包含完整的"思考 → 调用工具 → 观察结果 → 迭代修正"过程。本数据集在 MCPMark 框架基础上,针对MCP识别以及调用能力特征进行任务筛选与难度校准,聚焦于符合真实场景、依赖MCP且有较高难度的任务,生产出具有最高训练价值的 SFT/RL 数据。Playwright 作为浏览器交互执行载体,可支持多页面导航、信息提取与流程闭环,能够有效还原真实 Web 操作场景。作为本数据集的 MCP Server,用于训练模型在真实网页上的浏览能力,以及对页面信息的提取、整理与进一步计算分析的能力。
二、数据详情(500条)
类别
500 个任务覆盖了 22 个不同 category,任务间无明显重复:
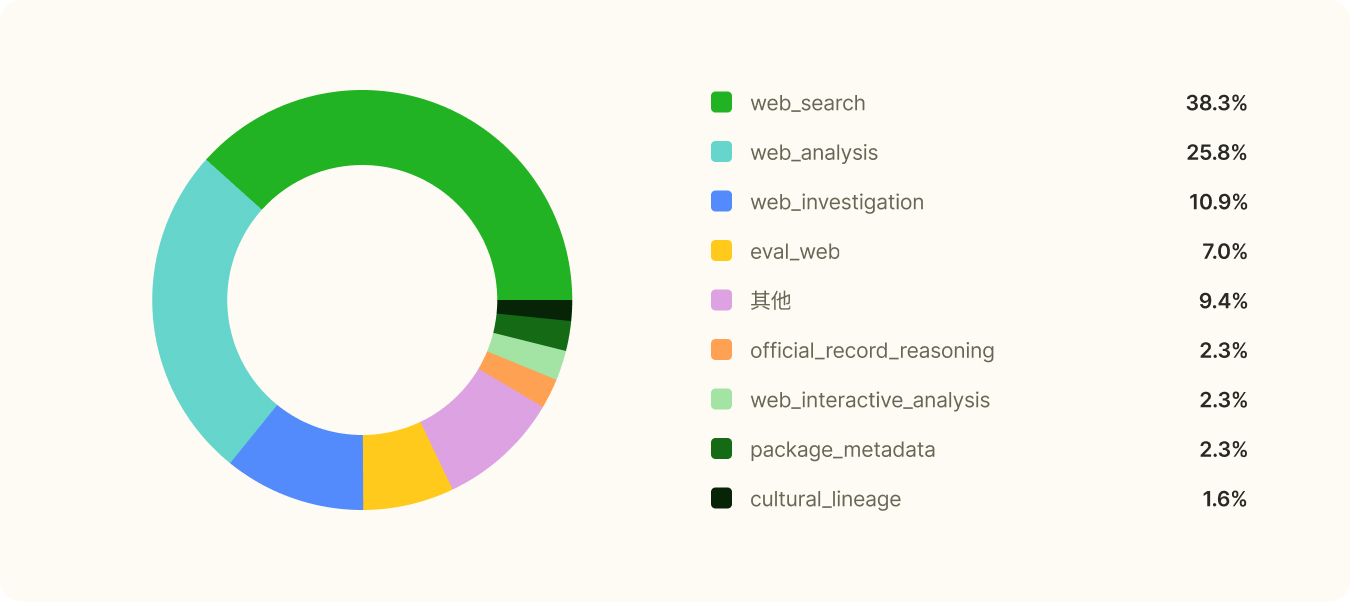
其他:课程调度、新闻排版、软件包架构分析、Django 回滚审计、事件最小修复、版本演进分析、Wiki 数据推理、创意静态操作、后台异常分析、舞台编排、依赖桥接、官方档案过滤等
难度
任务整体聚焦于 L3 中高难度区间:
-
这是经过专家试标后筛选出的"最具训练价值"的难度区间——既对模型构成真实挑战,又不至于让模型完全无从下手。L3 任务的核心特征在于多步骤工具调用链和跨页面状态管理。模型需要在单次会话中完成"导航→提取→推理→输出"的完整闭环,任何中间步骤的失误都会导致最终验证失败。
-
例如 Wikipedia 链接链探索任务要求访问 15+ 页面并逐一核验 6 个约束条件;大规模表格导出任务需要在分页加载和数据一致性之间保持精确同步。
-
部分任务在 L3 基础上进一步拓展了更高的难度上限,表现为多轮迭代修正能力要求、多维度交叉推理、以及 Cell 级精确验证等特征。这些挑战性任务主要分布在 web_analysis 和 web_investigation 类别。
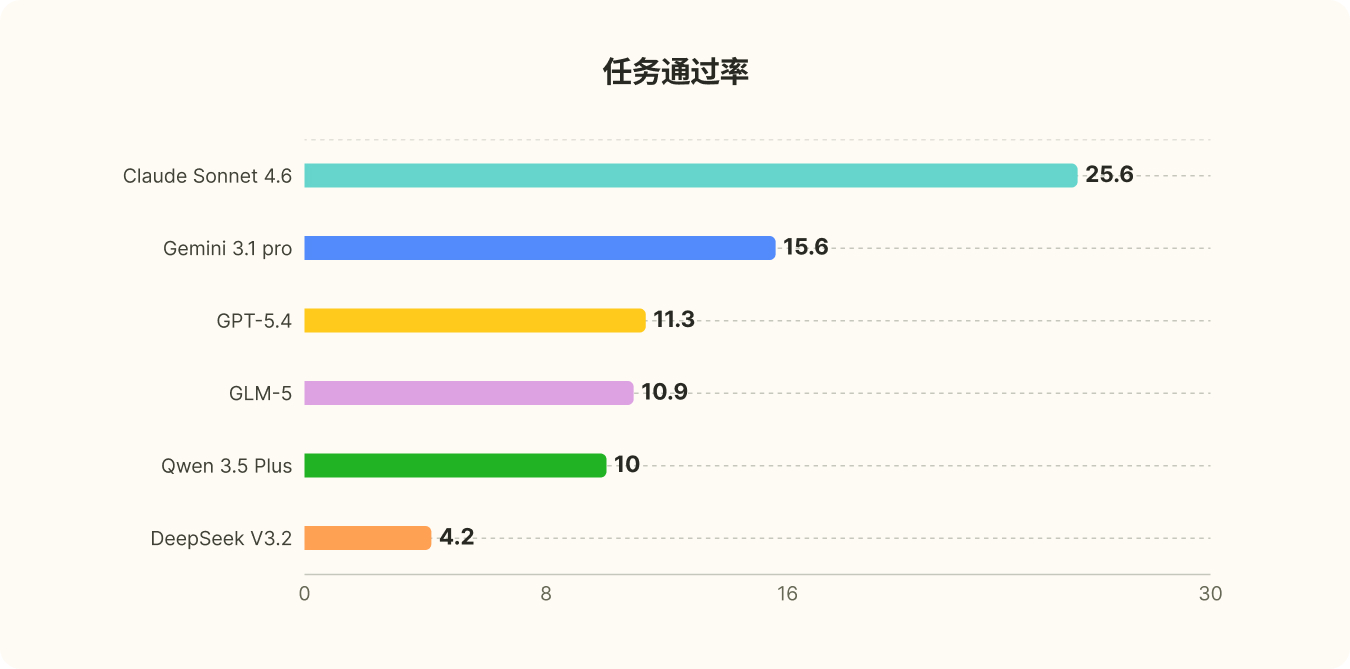
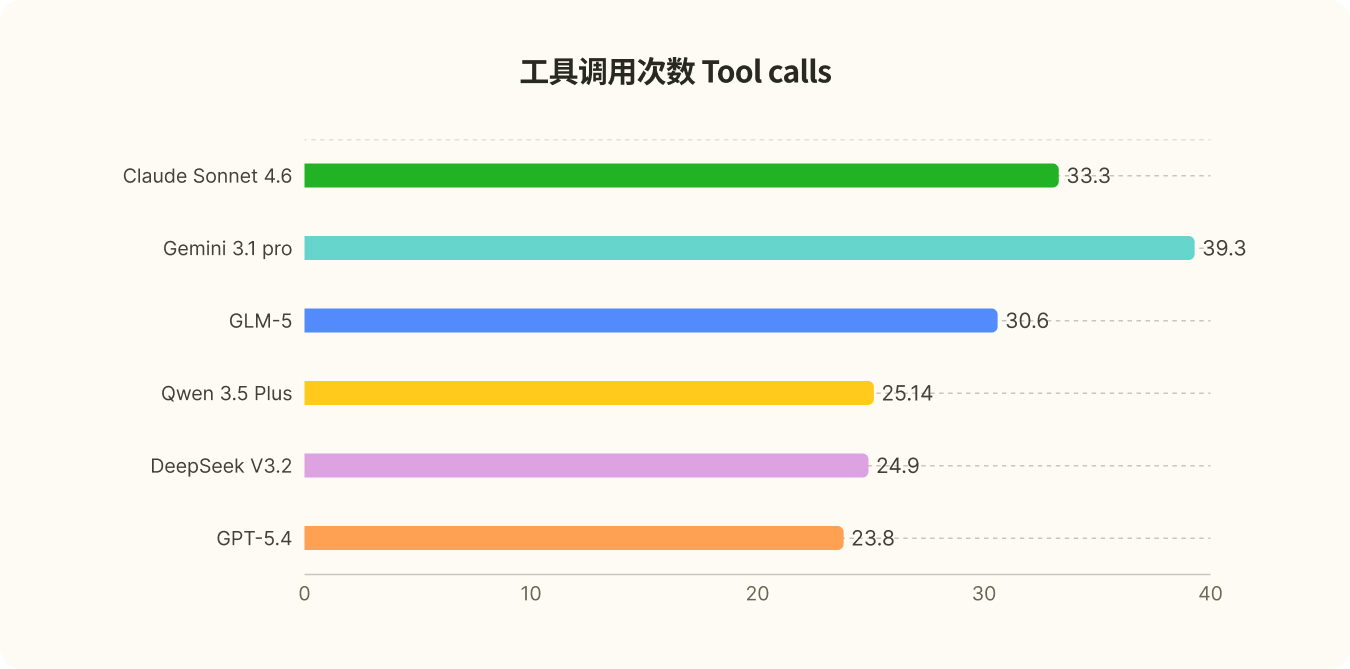
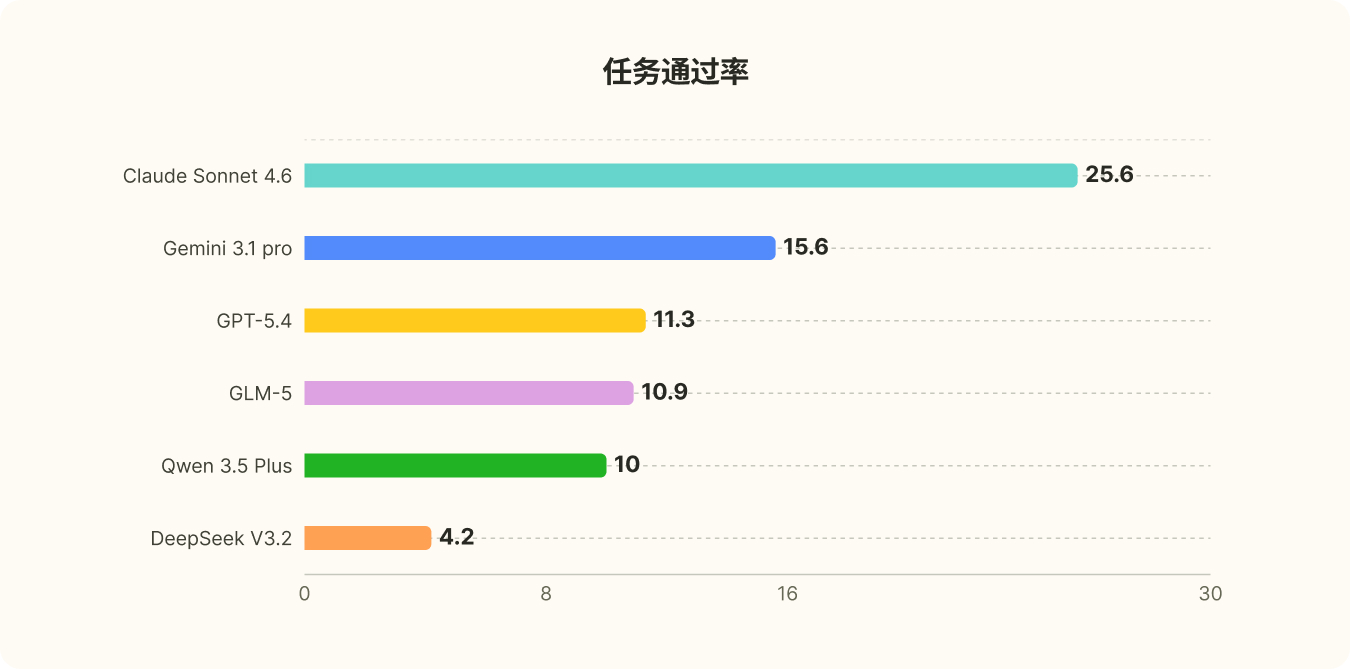
Tips:Turns:模型交互的轮数,包含最终的 answer 输出
Tool calls:模型的工具调用次数
PassRate@4
Tool calls
Turns
三、数据生产
3.1 复合型专家设计团队画像
本次数据集所有任务均由具备"人类复杂网页交互思维+工程化落地能力"的复合型技术专家设计,专家核心要求如下:
-
专业背景:计算机/理工科相关专业,具备Web自动化、前端开发、测试开发/爬虫项目经验,或拥有复杂信息检索与多源推理分析能力;
-
核心能力:
-
任务设计能力:将真实Web交互抽象为标准化评测任务,覆盖多级导航、跨页面提取、多条件筛选,保证任务唯一解、合理难度、交互复杂度;
-
Playwright工程能力:精通DOM解析、选择器定位、多窗口/Iframe处理,能应对动态加载/事件驱动的Web场景;
-
环境搭建能力:可构建本地隔离沙箱,复现稳定的Web交互场景,完成脚本调试与问题定位;
-
验证判分能力:使用Python编写自动化校验逻辑,实现对模型输出的结构化、标准化验证。
3.2 生产流程
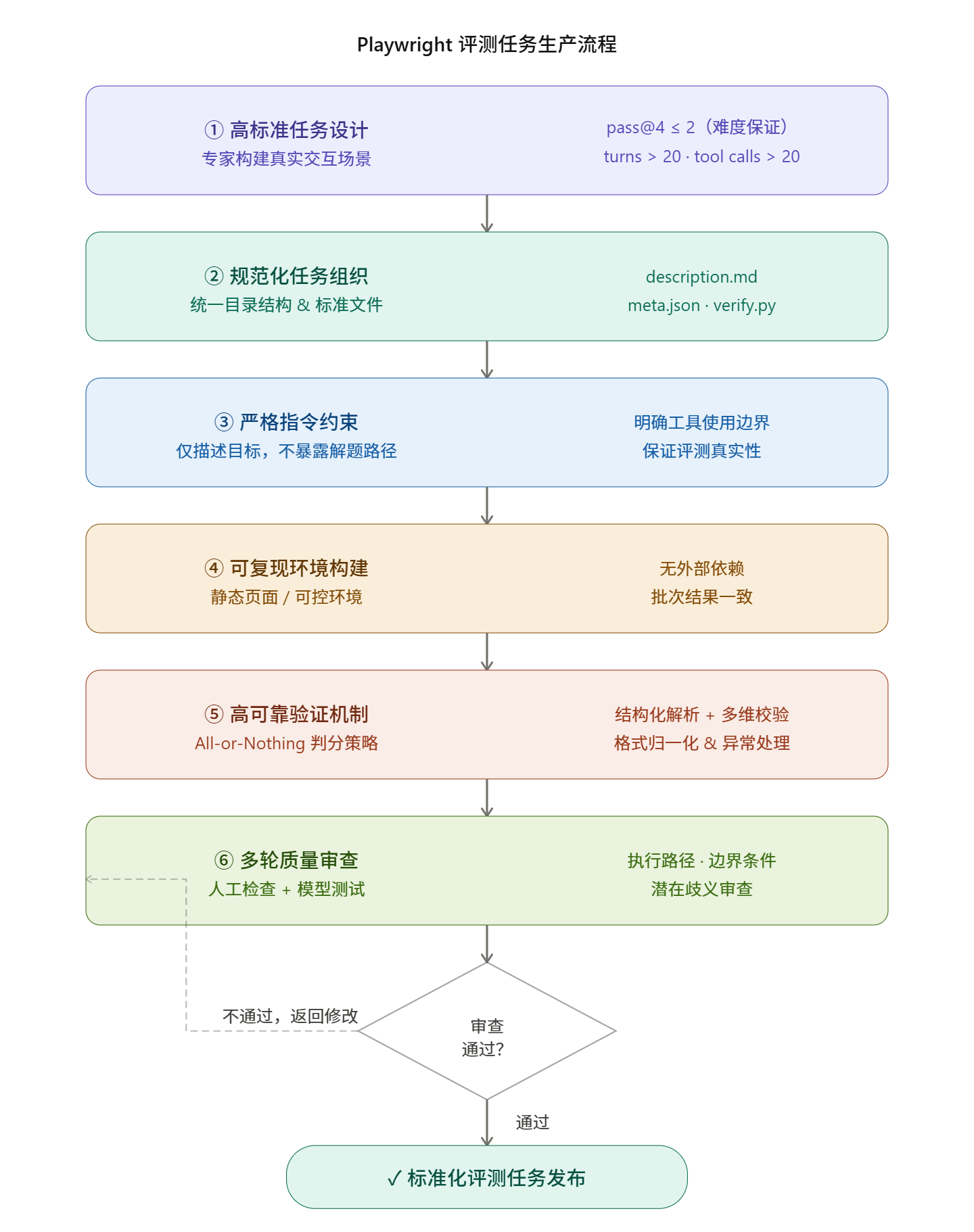
为保证 Playwright 评测数据的专业性、稳定性与区分度,所有任务均由专家按统一规范设计并经多轮审查,形成标准化生产流程:
-
专家基于真实网页交互场景构建任务,严格控制难度与复杂度,确保人工可稳定完成;
-
采用统一目录结构与标准文件配置,保障任务可追溯与系统可调度;
-
指令仅描述目标与约束、不暴露解题路径,明确工具边界以保证评测真实;
-
依托静态页面或可控环境搭建可复现场景,消除外部依赖与随机干扰;
-
验证脚本采用 All-or-Nothing 判分策略,结合结构化解析与多维校验保障公平可靠;
-
最终经多轮人工与模型测试审查后,发布标准化评测任务。
3.3 质量控制流程
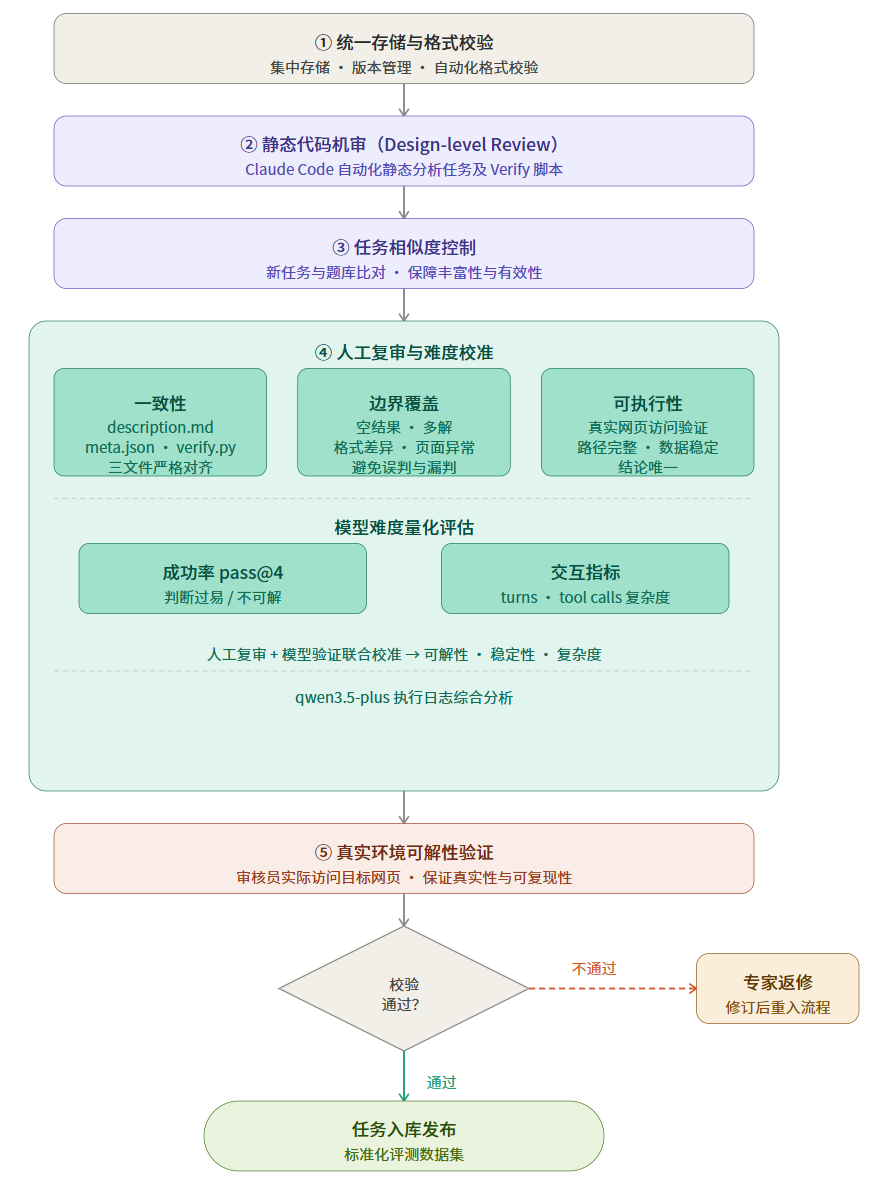
为确保 Playwright 评测数据集具备高可靠性、低噪声与良好区分度,项目建立全流程质量控制机制,对任务从产出到入库进行严格管控:
-
任务先经集中存储、版本管理与自动化格式校验,再通过 Claude Code 完成静态代码机审,随后与题库比对相似度以保障丰富性;
-
进入人工复审与难度校准阶段:
-
一致性:description.md、meta.json 与 verify.py 在任务目标、执行路径与判分标准上严格对齐;
-
边界覆盖:覆盖空结果、多解、格式差异及页面异常等情况,避免误判与漏判;
-
可解性:每道题目均由两名审核员进行网页实际访问验证。通过双重人工校验,确保任务路径闭环、数据表现稳定,并产出唯一确定的标准答案。我们设计了难度筛选与返修机制:对于在基准模型 Qwen3.5-Plus 上 pass@4 > 50% 的题目,判定为难度偏低,统一进入返修流程,指导专家进行题目难度调整与优化,确保任务具备充分的区分度与挑战性。在此基础上,引入基于模型的难度量化评估:
-
成功率(pass@4):用于判断任务是否过易或不可解;
-
交互指标(turns / tool calls):用于评估任务链路复杂度与探索空间,识别路径过短或异常循环等问题。通过"人工复审 + 模型验证"的联合校准机制,审核员从结果与过程两个维度对任务进行严格把控,确保数据在可解性、稳定性与复杂度上的一致标准,保障整体评测的专业性与可靠性。
- 经真实环境可解性验证,未通过的任务退回专家修订形成闭环,通过后入库发布标准化评测数据集。
四、Sample Data
宁德时代股份回购金额查询
| 字段 | 内容 |
|---|---|
| 任务 | catl_buyback_amount |
| 描述 | 在巨潮资讯网搜索"宁德时代",按日期 2023-11-02 筛选,找到股份回购公告,提取回购资金总额范围,输出精确格式的金额描述。 |
| Model | PassRate | Turns | Tool Calls |
|---|---|---|---|
| Qwen3.5-Plus | 0/4 | 29 | 29 |
| DeepSeek V3.2 | 1/4 | 21 | 20 |
| GLM-5 | 1/4 | 35 | 34 |
| GPT-5.4 | 0/4 | 18 | 17 |
| Gemini 3.1 Pro | 0/4 | 25.6 | 24 |
| Claude Sonnet 4.6 | 0/4 | 19.33 | 18.33 |
| 字段 | 内容 |
|---|---|
| Tips | 金融信息类,涉及精确的数据提取与计算 |
| Links | https://mcp-public.tos-cn-beijing.volces.com/mcpmark-new-sample/768451869d6a13b9e68039765efbaf523717ddbe6dc0362910163d8bd020ef15.zip |
| 经专家校验的解题路径 | 1. 任务定位与候选筛选:从巨潮资讯网首页出发,搜索"宁德时代",定位到公司公告列表页。 2. 日期与关键词筛选:从发布日期筛选 2023-11-02 的公告,找到标题含"回购股份"或"股份回购"的公告,进入公告正文。 3. 金额信息定位:在公告正文中定位"回购资金总额"相关描述,提取金额范围数据。 4. 目标任务确定:根据搜索筛选结果,确定目标公告为宁德时代 2023-11-02 发布的股份回购公告。 5. 多源信息聚合: - 公告标题:股份回购报告 - 发布时间:2023-11-02 - 回购资金总额范围:不低于人民币 20 亿元(含本数)且不超过人民币 30 亿元 6. 答案组装。 |
ApacheJMeter_core 依赖版本对比
| 字段 | 内容 |
|---|---|
| 任务 | apache_jmeter_core_dependency_comparison |
| 描述 | 从 Maven Repository 页面提取 ApacheJMeter_core 5.5 和 5.4.1 版本的依赖库,进行跨版本对比分析,输出新增、修改和移除的依赖项。 |
| Model | PassRate | Turns | Tool Calls |
|---|---|---|---|
| Qwen3.5-Plus | 1/4 | 23.75 | 24.75 |
| DeepSeek V3.2 | 1/4 | 18 | 17 |
| GLM-5 | 0/4 | 24 | 23 |
| GPT-5.4 | 0/4 | 13 | 12 |
| Gemini 3.1 Pro | 3/4 | 22.3 | 21.3 |
| Claude Sonnet 4.6 | 2/4 | 21.67 | 21 |
| 字段 | 内容 |
|---|---|
| Tips | 计算机文档分析类,辅助程序员进行版本比对与校准 |
| Links | https://mcp-public.tos-cn-beijing.volces.com/mcpmark-new-sample/aa346f7a8a8aec6db158d94247ec0d75c228de4e06fcb1a526a36b6cea35cfc0.zip |
| 经专家校验的解题路径 | 1. 任务定位与候选筛选:从 Maven Central / MVNRepository 出发,定位 Apache JMeter Core 的两个已发布版本依赖信息。 2. 版本依赖集合构建:分别拉取 5.5 与 5.4.1 的依赖列表,统一依赖坐标(groupId:artifactId),构建两个对比用集合。 3. 依赖差异计算:基于依赖列表进行集合运算,标记新增 / 移除 / 版本号变化三类差异。 4. 目标结果确定:根据差异分类规则,产出 Added / Modified / Removed 三类集合。 5. 多源信息聚合(核心信息抽取): - Added - Modified - Removed通过官方依赖列表页面与 mvnrepository 版本对比工具交叉验证,确保结果一致。 6. 答案组装。 |
药品审批多轮合规核验
| 字段 | 内容 |
|---|---|
| 任务 | fda_drug_approval_compliance_verification |
| 描述 | 访问 NIH DailyMed 药品数据库,对四种药品进行四轮验证:按首次批准年份筛选合格药品、按适应症数量排名、从不同标签部分提取字段、通过派生计算得出最终结果。 |
| Model | PassRate | Turns | Tool Calls |
|---|---|---|---|
| Qwen3.5-Plus | 0/4 | 24 | 23 |
| DeepSeek V3.2 | 0/4 | 20 | 19 |
| GLM-5 | 0/4 | 41 | 40 |
| GPT-5.4 | 1/4 | 43 | 42 |
| Gemini 3.1 Pro | 0/4 | 43 | 42 |
| Claude Sonnet 4.6 | 0/4 | 28.3 | 27.3 |
| 字段 | 内容 |
|---|---|
| Tips | 药品信息整理类,涉及医学领域繁杂的数据 |
| Links | https://mcp-public.tos-cn-beijing.volces.com/mcpmark-new-sample/65453f0ffb6c57c591e35e589df635c4954ccd659f2cf5757c06d3317c5d5096.zip |
| 经专家校验的解题路径 | 1. 任务定位与候选筛选:从 DailyMed 首页出发,搜索 Humira、Avastin、Revlimid、Keytruda,定位各自官方药品标签页面。 2. 首次批准年份筛选:从 Label Header 提取 "Initial U.S. Approval",筛选批准年份 ≤ 2010 的药物,得到候选集合。 3. 适应症数量统计与排序:进入 "INDICATIONS AND USAGE" 章节,对编号标题数量进行计数,并按降序排序。 4. 目标任务确定:根据排序结果,确定 Rank1 = Humira,Rank2 = Avastin,Rank3 = Revlimid。 5. 多源信息聚合: - Rank1(Humira) - Rank2(Avastin) - Rank3(Revlimid) - Excluded(Keytruda) 6. 答案组装:拼接 16 个字段并完成派生计算。 |
NASA 任务巡航时间排名与重力辅助分析
| 字段 | 内容 |
|---|---|
| 任务 | nasa_mission_travel_median |
| 描述 | 从 NASA 任务 Hub 页出发,通过官方导航找到目标天体任务页,筛选运载火箭家族后按巡航时间排序,选第二长任务并查找其重力辅助行星数量、运载火箭和发射场的精确官方措辞。 |
| Model | PassRate | Turns | Tool Calls |
|---|---|---|---|
| Qwen3.5-Plus | 1/4 | 26.25 | 25.25 |
| DeepSeek V3.2 | 0/4 | 24 | 24 |
| GLM-5 | 0/4 | 32 | 31 |
| GPT-5.4 | 0/4 | 25.1 | 24 |
| Gemini 3.1 Pro | 1/4 | 42.3 | 41 |
| Claude Sonnet 4.6 | 2/4 | 50.2 | 49.5 |
| 字段 | 内容 |
|---|---|
| Tips | 科学计算类,符合真实场景的需求 |
| Links | https://mcp-public.tos-cn-beijing.volces.com/mcpmark-new-sample/44b7eef9460e92dbea3bb2d6e09ae8142e208ac394f96076484b5880731a5fc9.zip |
| 经专家校验的解题路径 | 1. 任务定位与候选筛选:从 NASA Missions 入口页出发,定位各 target bodies 对应的官方 mission。 2. 运载火箭家族过滤:筛选 launch vehicle 属于 Atlas V 或 Titan IV/Centaur family 的 mission,得到候选集合。 3. 巡航时间计算与排序:从官方页面获取 launch date 与 first arrival date,计算 cruise duration 并升序排序。 4. 目标任务确定:根据题意选取"第二长 cruise duration",确定目标 mission 为 Cassini-Huygens。 5. 多源信息聚合(核心信息抽取): - Gravity Assist 数量 - Launch Vehicle - Launch Site 6. 答案组装。 |
arXiv 高引用 NLP 论文发现
| 字段 | 内容 |
|---|---|
| 任务 | arxiv_related_paper_discovery |
| 描述 | 通过多阶段筛选在 arXiv 发现高引用 NLP 论文:从 cs.CL 类别过滤到 cs.AI/cs.LG 交叉分类,验证发表时间、Transformer 关键词、作者论文数和外部引用数,最终返回引用最高的论文。 |
| Model | PassRate | Turns | Tool Calls |
|---|---|---|---|
| Qwen3.5-Plus | 0/4 | 15 | 14 |
| DeepSeek V3.2 | 0/4 | 14 | 14 |
| GLM-5 | 0/4 | 27 | 26 |
| GPT-5.4 | 0/4 | 17 | 16 |
| Gemini 3.1 Pro | 1/4 | 26.33 | 26 |
| Claude Sonnet 4.6 | 2/4 | 37 | 36 |
| 字段 | 内容 |
|---|---|
| Tips | 文献调研类,严谨的科研任务需求 |
| Links | https://mcp-public.tos-cn-beijing.volces.com/mcpmark-new-sample/e8fb6b1dd5f4e5f096e3b210c7eae50c9758ad788646d8c1ff7df45689a07eb0.zip |
| 经专家校验的解题路径 | 1. 任务定位与候选筛选:从 arXiv 高级搜索入口出发,设置分类条件 cs.CL +(cs.AI 或 cs.LG)及时间范围 2020–2023,获取候选论文列表。 2. 关键词与分类筛选:访问候选论文页面,读取摘要内容,筛选包含 "transformer" 或 "attention" 关键词且标题不包含 "BERT" 的论文。 3. 作者论文数与引用数筛选:访问作者 arXiv 页面统计论文总数(≥5),并通过 Semantic Scholar / Google Scholar 获取引用数(≥100),筛选全部满足条件的论文集合。 4. 目标任务确定:在通过所有筛选的论文中对引用数降序排序,确定引用最高者作为目标论文。 5. 多源信息聚合: - arXiv 页面 - 作者页面 - 引用来源 - 内容验证 6. 答案组装。 |
五、cases 说明
Gemini turns 和 tool calls 异常突出
1) 环境配置与工具链正常,不是基础设施问题
从运行日志看,Playwright 相关依赖已正确安装并可用,且工具集完整加载(browser_install / browser_navigate / browser_run_code 等核心工具均可调用),无报错。同时,同批次存在可通过样本(如 59 turns 完成),因此可以判定瓶颈来自模型自身的调用策略,而非任务本身不合理或环境不可运行。
2) 失败主要由模型过度调用导致(snapshot / run_code 过多),触发 100 turn 上限
失败样本的共性不是"执行中断",而是"执行过度":模型在已获得部分有效信息后,仍持续进行高频、低增益的 snapshot 与 run_code 调用,且多次调用在目标与代码结构上高度重复,导致对话轮次和工具调用数同步拉满(典型为 100 turns / 100 tool calls)。这类轨迹反映的是策略不收敛:模型没有及时从"探索阶段"切换到"答案收敛阶段",最终在规则上触发 Max turns (100) exceeded。因此,问题本质是模型执行策略偏离,而非任务本身不合理或环境不可运行。
GPT-5.4成功率分析
GPT 在执行复杂任务时,因理解不充分或路径规划失误而中途放弃,主要体现在以下几个方面:
-
任务理解不充分导致早停:GPT 未能准确把握任务的整体结构与最终目标,对关键约束条件或隐含要求理解不完整。在执行过程中,一旦发现当前操作路径与预期结果出现偏差,往往倾向于直接停止,而不是进行回溯、修正策略或重新规划执行路径,表现出较弱的自纠错能力。
-
低估任务复杂度与资源分配不足:GPT 容易对任务难度产生误判,未能合理预估所需的交互轮数与信息获取成本,导致在执行过程中因轮数限制或上下文不足而被迫终止。同时,其信息获取与验证流程往往不完整,缺乏多步验证与冗余检查机制,使任务在尚未充分收敛时提前结束。
-
线性执行思维限制任务完成度:GPT 通常将复杂任务建模为强依赖的线性流程,对步骤之间的依赖关系过于刚性。一旦某一关键步骤失败,便倾向于判定整体任务不可继续执行,而缺乏将任务拆解为多个相对独立子任务的能力,也较少进行并行路径探索或备选方案尝试,最终导致任务提前终止。